 Traducciones:
Traducciones:
Esta traducción se concluyó, el 3 de enero de 2001.
Los posibles errores presentes en este documento, debidos a la traducción, son de la responsabilidad del traductor y no son achacables en modo alguno al W3C. Para cualquier comentario sobre la traducción dirigirse a Eva Méndez, Miembro del G2 del SIDAR.
La única versión normativa oficial de este documento es la versión original (en inglés):
http://www.w3.org/TR/REC-rdf-syntax/
 REC-rdf-syntax-19990222-es
REC-rdf-syntax-19990222-es
Resource Description Framework(RDF)
Especificación del Modelo y la Sintaxis
Recomendación del W3C 22 febrero 1999 (español)

- Esta versión:
- http://www.w3.org/TR/1999/REC-rdf-syntax-19990222
- Última versión:
- http://www.w3.org/TR/REC-rdf-syntax
- Editores:
- Ora
Lassila mailto:ora.lassila@research.nokia.com,
Nokia Research Center
Ralph R. Swick mailto:swick@w3.org,
World Wide Web Consortium
Estado del
Documento
Copyright
© 1997,1998,1999 W3C (MIT, INRIA, Keio
), Todos los derechos reservados. W3C reponsabilidad
legal, marca
registrada, uso del
documento y aplicación de las reglas de licencia de
software.
Copyright © de la traducción: 2000, Eva Méndez
Se ha tratado de respetar al máximo el contenido de la
especificación original en inglés, adaptando la expresión al español e
introduciendo entre [corchetes] algunas palabras (bien en español o en
inglés) que ayuden a una mejor comprensión de esta especificación a
investigadores e interesados en XML/RDF del dominio lingüístico español.
No obstante, puden haberse cometido errores fruto de la traducción;
por ello, ha de tenerse en cuenta que la única especificación
válida es la que está en inglés en la dirección original del W3C:
http://www.w3.org/TR/REC-rdf-syntax/
|
Estado de este documento
Los miembros del Consorcio WWW (W3C) y otras partes interesadas
han revisado este documento y el director lo ha aprobado como Recomendación W3C. Es
un documento estable que se utilizará como material de referencia o se citará
como referencia normativa en otros documentos. El papel del W3C al elaborar la
Recomendación es llamar la atención sobre la especificación y promover un
desarrollo generalizado de la misma. Esto enriquece la operatividad e
interoperabilidad del Web.
Se puede acceder a la lista de errores conocidos en esta
especificación [en inglés]: http://www.w3.org/TR/1999/REC-rdf-syntax-19990222/errata.
Se pueden enviar comentarios a la especificación a <www-rdf-comments@w3.org>. El
archivo de comentarios públicos se puede consultar en: http://www.w3.org/Archives/Public/www-rdf-comments.
Tabla de contenido [índice]:
- Introducción
- RDF
Básico
- Contenedores
- Declaraciones
sobre declaraciones
- Modelo
formal para RDF
- Gramática
formal para RDF
- Ejemplos
- Agradecimientos
- Anexo
A: Glosario
- Anexo
B: Transmisión RDF
- Anexo
C: Notas sobre el uso
- Anexo
D: Referencias
- Anexo
E: Modificaciones
1. Introducción
En un principio la World Wide Web se construyó para el uso
humano, y a pesar de que todo en ella era legible por máquina estos datos
todavía no son legibles por ésta última. Es muy difícil automatizar cualquier
cosa en la Web, debido al volumen de información que contiene, no es posible
gestionarla manualmente. La solución que se propone aquí es el uso de
metadatos para describir los datos contenidos en la Web. Los metadatos
son "datos sobre los datos" (por ejemplo, un catálogo de biblioteca es [un
registro] de metadatos, en el sentido de que describen publicaciones) o
concretamente en el contexto de esta especificación "datos que describen
recursos Web". La distinción entre "datos" y "metadatos" no es incuestionable;
es una diferencia creada en primera instancia por una aplicación particular, y
muchas veces el mismo recurso se interpretará de ambas formas [como dato y como
metadato] simultáneamente.
Resource Description Framework (RDF) [Infraestructura para la
Descripción de Recursos] es una base para procesar metadatos; proporciona
interoperabilidad entre aplicaciones que intercambian información legible por
máquina en la Web. RDF destaca por la facilidad para habilitar el
procesamiento automatizado de los recursos Web. RDF puede utilizarse en
distintas áreas de aplicación; por ejemplo: en recuperación de recursos
para proporcionar mejores prestaciones a los motores de búsqueda, en
catalogación para describir el contenido y las relaciones de contenido
disponibles en un sitio Web, una página Web, o una biblioteca digital
particular, por los agentes de software inteligentes para facilitar el
intercambio y para compartir conocimiento; en la calificación de
contenido, en la descripción de colecciones de páginas que
representan un "documento" lógico individual, para describir los
derechos de propiedad intelectual de las páginas web, y para expresar las
preferencias de privacidad de un usuario, así como las políticas de
privacidad de un sitio Web. RDF junto con las firmas digitales será
la clave para construir el "Web de confianza" para el comercio electrónico, la
cooperación y otras aplicaciones.
Este documento introduce un modelo para representar metadatos
en RDF así como una sintaxis para codificar y transmitir estos metadatos de tal
forma que maximicen la interoperabilidad de servidores y clientes web
desarrollados independientemente. La sintaxis presentada aquí utiliza el
Extensible Markup Language [Lenguaje de Marcado Extensible] (XML): uno de los
objetivos de RDF es hacer posible especificar la semántica para las bases de
datos en XML de una forma normalizada e interoperable. RDF y XML son
complementarios: RDF es un modelo de metadatos y sólo dirige por referencia
muchos de los aspectos de codificación que requiere el almacenamiento y
transferencia de archivos (tales como internacionalización, conjuntos de
caracteres, etc.). Para estos aspectos, RDF cuenta con el soporte de XML. Es
importante también entender que esta sintaxis XML es sólo una sintaxis posible
para RDF y que pueden surgir formas alternativas para representar el mismo
modelo de datos RDF.
El objetivo general de RDF es definir un mecanismo para
describir recursos que no cree ninguna asunción sobre un dominio de aplicación
particular, ni defina (a priori) la semántica de algún dominio de aplicación. La
definición del mecanismo debe ser neutral con respecto al dominio, sin embargo
el mecanismo debe ser adecuado para describir información sobre cualquier
dominio.
Esta especificación continuará con otros documentos que
completarán el marco. Sobre todo, para facilitar la definición de metadatos, RDF
contará con un sistema de clasificación muy parecido a los sistemas de
programación y modelado orientado a objetos. Una
colección de categorías (producida normalmente para un propósito o dominio
específico) denominada schema. Las categorías se organizan en una
jerarquía, y proporcionan extensibilidad a través de un refinamiento de
subcategorías. Así, para crear un esquema ligeramente diferente de uno existente
no es necesario "reinventar la rueda" pero se pueden facilitar modificaciones
incrementales al esquema base. A través de la compartición del esquema RDF
soportará la reutilización de definiciones de metadatos. Gracias a la
extensibilidad incremental de RDF, los agentes que procesen metadatos serán
capaces de trazar los orígenes del esquema que no conocen con respaldo
para conocer el esquema y realizar acciones significativas en los metadatos que
no han sido diseñados inicialmente para procesar. La capacidad de
compartir y la extensibilidad de RDF permiten a los creadores de metadatos usar
múltiples cambios de la categoría de objetos para "mezclar" definiciones, para
proporcionar múltiples presentaciones a sus datos, haciendo uso del trabajo de
otros. En síntesis, es posible crear objetos específicos de datos basados en
diversos esquemas de distintas fuentes (p. ej. "intercalando" diferentes tipos
de metadatos). Los esquemas pueden escribirse en RDF; un documento que
acompaña a esta especificación [RDFSchema], describe un
conjunto de propiedades y clases para describir esquemas RDF.
Como resultado de la reunión de distintas comunidades que están
de acuerdo en los principios básicos de la representación y transposición de
metadatos, RDF está influido de varias fuentes diferentes. Las principales
influencias provienen de la propia Comunidad de Normalización de la
Web en forma de metadatos HTML y PICS, la comunidad bibliotecaria, la
comunidad de los documentos estructurados en forma de SGML y sobre todo
XML, y también de la comunidad de representación del conocimiento (KR).
También han contribuido al diseño de RDF otras áreas de la tecnología; incluidos
los lenguajes de modelado y programación orientada a objetos, así como las bases
de datos. Mientras RDF surge de la comunidad KR [de la representación del
conocimiento], la bibliografía relacionada con este campo, advierte que RDF no
especifica un mecanismo para el razonamiento. RDF puede definirse como un
sistema simple. Un mecanismo de razonamiento debe construirse sobre este sistema
de referencia.
2. RDF Básico
2.1. Modelo RDF básico
El fundamento o base de RDF es un modelo para representar
propiedades designadas y valores de propiedades. El modelo RDF se basa en
principios perfectamente establecidos de varias comunidades de representación de
datos. La propiedades RDF pueden recordar a atributos de recursos y en este
sentido corresponden con los tradicionales pares de atributo-valor. Las
propiedades RDF representan también la relación entre recursos y por lo tanto,
un modelo RDF puede parecer un diagrama entidad-relación. (De forma más precisa,
los esquemas RDF —que son objetos específicos de la categoría del modelo de
datos RDF — son diagramas ER [Entidad Relación]. En la terminología del diseño
orientado a objetos, los recursos corresponden con objetos y las propiedades
corresponden con objetos específicos y variables de una categoría.
El modelo de datos de RDF es una forma de sintaxis-neutral para
representar expresiones RDF. La representación del modelo de datos se usa para
evaluar la equivalencia en significado. Dos expresiones RDF son equivalentes y y
sólo si sus representaciones del modelo de datos son las mismas. Esta definición
de equivalencia permite algunas variaciones sintácticas en expresiones sin
alterar el significado. (Ver Sección
6 para discusión adicional del tema de comparación strings [series de
caracteres entendidas como grupos].
El modelo de datos básico consiste en tres tipos de objetos:
| Recursos |
Todas las cosas descritas por expresiones RDF se
denominan recursos. Un recursos puede ser una página Web completa;
tal como el documento HTML "http://www.w3.org/Overview.html" por ejemplo.
Un recurso puede ser una parte de una página Web; p. ej. un elemento HTML
o XML específico dentro del documento fuente. Un recurso puede ser también
una colección completa de páginas; p. ej. un sitio Web completo. Un
recurso puede ser también un objeto que no sea directamente accesible vía
Web, p. ej. un libro impreso. Los recursos se designan siempre por URIs
más identificadores de anclas opcionales (ver [URI]).
Cualquier cosa puede tener un URI; la extensibilidad de URIs permite la
introducción de identificadores para cualquier entidad
imaginable. |
| Propiedades |
Una propiedad es un aspecto específico,
característica, atributo, o relación utilizado para describir un recurso.
Cada propiedad tiene un significado específico, define sus valores
permitidos, los tipos de recursos que puede describir, y sus relaciones
con otras propiedades. Este documento no dirige cómo se expresan las
características de las propiedades; para tal información, dirigirse a la
especificación del esquema RDF [RDF Schema
specification]. |
Sentencias
[declaraciones,
enunciados] |
Un recurso específico junto con una propiedad denominada,
más el valor de dicha propiedad para ese recurso es una sentencia RDF
[RDF statement]. Estas tres partes individuales de una sentencia se
denominan, respectivamente, sujeto, predicado y objeto. El objeto de una
sentencia (es decir, el valor de la propiedad) puede ser otro recurso o
pude ser un literal; es decir, un recurso (especificado por un URI) o una
cadena simple de caracteres [string] u otros tipos de datos primitivos
definidos por XML. En términos RDF, un literal puede comprender en
su contenido marcado XML pero ya no puede valorarse más por un procesador
RDF. Existen varias restricciones sintácticas en cómo se puede expresar el
marcado en literales.; ver Sección
2.2.1. |
2.1.1. Ejemplos
Los recursos se identifican por un identificador de
recursos. Un identificador de recursos es un URI más un identificador
opcional de ancla (ver sección 2.2.1.).
Para el propósito de esta sección, las propiedades se referirán a través de un
nombre simple.
Considerar como ejemplo simple la sentencia:
Ora Lassila es el creador [autor] del
recurso http://www.w3.org/Home/Lassila.
Esta sentencia
comprende las siguientes partes:
| Sujeto (Recurso) |
http://www.w3.org/Home/Lassila |
| Predicado (Propiedad) |
Creator |
| Objeto (literal) |
"Ora Lassila" |
En este documento podríamos representar gráficamente una
sentencia RDF usando gráficos etiquetados (también denominados "diagramas de
nodos y arcos"). En estos gráficos, los nodos (dibujados como óvalos)
representan recursos y los arcos representan propiedades denominadas. Los nodos
que representan cadenas de literales pueden dibujarse como rectángulos. La
sentencia citada anteriormente se representaría gráficamente como:
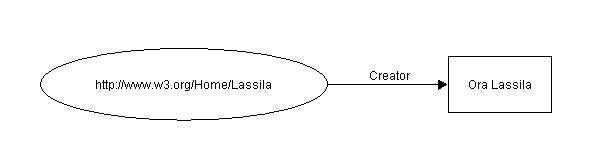 D
Figura 1: Diagrama de nodo y arco simples
D
Figura 1: Diagrama de nodo y arco simples
Nota: La dirección de la flecha es
importante. El arco siempre empieza en el sujeto y apunta hacia el objeto de
la sentencia. Este diagrama simple puede también interpretarse o leerse
"http://www.w3.org/Home/Lassila tiene como creador a Ora Lassila", o en
general "<sujeto> TIENE <predicado>
<objeto>".
Ahora, imaginemos que queremos decir algo más sobre las
características del creador de este recurso. Tal declaración en lenguaje natural
podría ser:
El individuo cuyo nombre es Ora Lassila,
correo electrónico <lassila@w3.org>, es el creador de
http://www.w3.org/Home/Lassila.
La intención de esta frase es precisar el valor de la propiedad
Creator [Creador] una entidad estructurada. En RDF tal entidad se
representa como otro recurso. La sentencia anterior no proporciona un nombre a
ese recurso; es anónimo, por ello el gráfico a continuación lo representa como
un óvalo vacío:
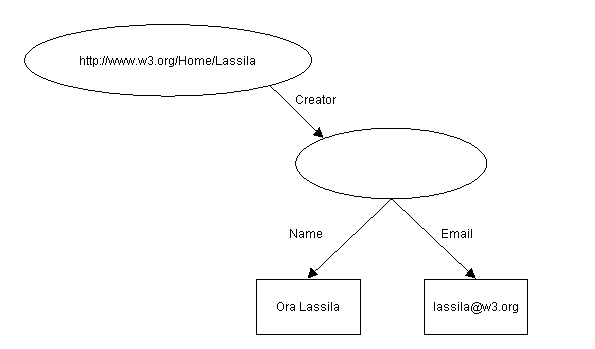 D
Figura 2: Propiedad con valor estructurado
D
Figura 2: Propiedad con valor estructurado
Nota: correspondiendo con la lectura de
la nota anterior, este diagrama puede leerse:
"http://www.w3.org/Home/Lassila tiene el creador cualquiera y este
cualquiera tiene el nombre Ora Lassila y el correo electrónico
lassila@w3.org".
A la entidad estructurada del ejemplo anterior se le puede
asignar un único identificador. El diseñador de la aplicación de la base de
datos hace la elección del identificador. Continuando con el ejemplo, imagine
que un identificador empleado se utiliza como único identificador para un
recurso "persona". Los URIs que sirven como única clave para cada empleado
(definido por la organización) podría ser entonces algo como:
http://www.w3.org/staffId/85740. Ahora podemos escribir dos frases o
sentencias:
El individuo al que se refiere el
identificador de empleado id 85740 se llama Ora Lassila y tiene la
dirección de correo lassila@w3.org. Ese individuo creó el recurso
http://www.w3.org/Home/Lassila
El modelo RDF para
estas frases o sentencias es:
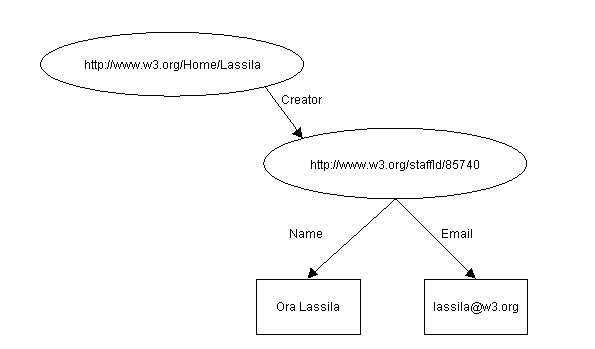 D
Figura 3: Valor estructurado con identificador
D
Figura 3: Valor estructurado con identificador
Obsérvese que este gráfico es idéntico al anterior con la
adición del URI para el recurso que antes era anónimo. Desde el punto de vista
de una segunda aplicación que interrogue este modelo, no hay distinción entre la
sentencia hecha de forma individual y la sentencia realizada por partes. Sin
embargo, algunas aplicaciones necesitarán hacer esta distinción y RDF lo
soporta; para más detalles ver Sección
4, Declaraciones sobre Declaraciones.
2.2. Sintaxis RDF básica
El modelo de datos RDF proporciona un marco abstracto y
conceptual para definir y utilizar metadatos. Necesita también una sintaxis
concreta para crear e intercambiar metadatos. Esta especificación de RDF utiliza
el [Lenguaje de Marcado eXtensible] Extensible Markup Language [XML]
codificado como su sintaxis de intercambio. RDF necesita también la [facilidad
de los namespaces XML] XML
namespace facility para asociar con precisión cada propiedad con el esquema
que define dicha propiedad; ver Sección 2.2.3., Esquemas
y Namespaces.
Las descripciones sintácticas en este documento usan la forma
de notación Extended Backus-Naur Form [EBNF] como se define en la Sección 6, Notación, de [XML] para describir los elementos
sintácticos esenciales en RDF. La EBNF aquí se abrevia [o concentra] para la
legibilidad humana, en particular la cursiva "rdf" se usa para
representar un prefijo de namespace variable más que la notación BNF más precisa
"'<' NSprefix ':...'". La condición es que la propiedad y el tipo de
nombres en las etiquetas finales coincidan con los nombres en las etiquetas
iniciales correspondientes implicadas en las reglas de XML. Todas la
flexibilidades sintácticas de XML están incluidas implícitamente, p. ej. las
reglas de espacio en blanco, citar usando tanto comillas simple (') como
comillas dobles ("), character escaping, case
sensibility, y marcado del lenguaje [language
tagging].
Esta especificación define dos sintaxis XML para codificar una
instancia [objeto específico de una categoría] de modelo de datos. La
sintaxis serializada expresa las capacidades totales del modelo de
datos de una forma muy regular. La sintaxis abreviada incluye términos
adicionales que proporcionan una forma más compacta para representar un
subconjunto del modelo de datos. Los intérpretes de RDF se han anticipado
a implementar ambas sintaxis, la serializada completa y la abreviada. Así, los
autores [creadores] de metadatos pueden mezclar ambas libremente.
2.2.1. Sintaxis serializada básica
Una sentencia [declaración] RDF rara vez aparece sola;
normalmente se darán juntas varias propiedades de un recurso. La sintaxis RDF
XML se ha diseñado para dar cabida a esto agrupando múltiples sentencias para el
mismo recursos en un elemento Description. El elemento
Description denomina, en un atributo about, el recurso para el
cual se aplica cada una de las sentencias [o declaraciones]. Si el recurso no
existe todavía (es decir, no tiene todavía un identificador de recursos)
el elemento Description puede proporcionar el identificador para el
recurso usando el atributoID.
La sintaxis serializada RDF básica toma la forma:
[1] RDF ::= ['<rdf:RDF>'] description* ['</rdf:RDF>']
[2] description ::= '<rdf:Description' idAboutAttr? '>' propertyElt*
'</rdf:Description>'
[3] idAboutAttr ::= idAttr | aboutAttr
[4] aboutAttr ::= 'about="' URI-reference '"'
[5] idAttr ::= 'ID="' IDsymbol '"'
[6] propertyElt ::= '<' propName '>' value '</' propName '>'
| '<' propName resourceAttr '/>'
[7] propName ::= Qname
[8] value ::= description | string
[9] resourceAttr ::= 'resource="' URI-reference '"'
[10] Qname ::= [ NSprefix ':' ] name
[11] URI-reference ::= string, interpreted per [URI]
[12] IDsymbol ::= (any legal XML name symbol)
[13] name ::= (any legal XML name symbol)
[14] NSprefix ::= (any legal XML namespace prefix)
[15] string ::= (any XML text, with "<", ">", and "&" escaped)
El elemento RDF es un simple envoltorio que
marca los límites en un documento XML entre los que el contenido está dispuesto
a ser mapeado a una instancia de modelo de datos RDF. El elemento
RDF es opcional si el contenido puede entenderse como RDF desde
el contexto de la aplicación.
El elemento Description contiene los elementos
sobrantes que posibilitan la creación de sentencias en la instancia [objeto
específico de la categoría] del modelo. El elemento Description
puede evocarse (con la finalidad de sintaxis RDF básica) simplemente como un
lugar donde mantener la identificación de un recuso descrito. Normalmente habrá
más de una sentencia [o declaración] sobre un recursos; el elemento
Description proporciona una forma de dar el nombre justo de una
vez a varias sentencias.
Cuando se especifica el atributo about con
Description, la sentencia [declaración] en el elemento
Description se refiere al recurso cuyo identificador determina
el elemento about. El valor del atributo about
se interpreta como una referencia-URI por Sección 4 del [URI]. El identificador de
recursos correspondiente se obtiene resolviendo la referencia-URI a la forma
absoluta como se especifica mediante [URI]. Si se incluye un fragmento del
identificador en la referencia-URI, el identificador de recursos se refiere sólo
al subcomponente del recurso que lo contiene, recurso que se identificará a
través del correspondiente fragmento ID interno a dicho recurso que lo
contiene (ver ancla en [Dexter94]),
por otra parte el identificador se refiere al recurso completo especificado por
el URI. Un elemento Description sin un atributo
about representa un nuevo recurso. Tal recurso podría ser un
substituto, o delegado [proxy], para algunos recursos físicos que no tienen un
URI reconocible. El valor del atributo ID del elemento
Description, en el caso de que se presente, es el ancla id de
ese recurso"in-line".
Si otro elemento Description o valor de
propiedad necesita referirse a el recurso in-line utilizará el valor del
ID de dicho recurso en su propio atributo about.
El atributo ID indica la creación de un nuevo recurso y el
atributo about se refiere a un recurso existente; por ello
tanto el atributo ID como about pueden
especificarse en el elemento Description pero no los dos juntos
en el mismo elemento. Los valores para cada atributo ID no deben
aparecer en más de un atributo ID dentro del mismo documento.
Un único elemento Description puede contener
más de un elemento propertyElt con el mismo nombre de propiedad.
Cada uno de dichos propertyElt añaden un arco al gráfico. La
interpretación de esta representación gráfica se definirá por el diseñador del
esquema.
Dentro del elemento propertyElt, el atributo
resource especifica que otros recursos son el valor de esta
propiedad; es decir, el objeto de la sentencia [o declaración] es otro recurso
identificado identificado por un URI preferentemente a la indicación por un
literal. El identificador del recurso del objeto se obtiene resolviendo el
URI-de referencia del atributo resource de la misma forma que se
mencionó anteriormente para el atributo about. Los
Strings deben ser XML bien formados; el XML convencional
contiene mecanismos de citación y disgregación que pueden usarse si la
serie de caracteres [string] contiene secuencias de caracteres (ej. "<" and
"&") que transgreden las reglas de buena formación o que podría parecer
"marcado". Ver Sección
6. para sintaxis adicional que especifique un valor de propiedad con
contenido XML bien formado y que conlleve marcado de tal forma que éste no sea
interpretado por RDF.
Los nombres de propiedad pueden asociarse con un esquema. Esto
puede hacerse cualificando los nombres de los elementos con un prefijo de
namespace que asocie con claridad la definición de propiedad con el
esquema RDF correspondiente o declarando un namespace por defecto como se
expresa en [NAMESPACES].
El ejemplo de la frase de la sección 2.1.1
Ora Lassila es el creador [autor] del
recurso http://www.w3.org/Home/Lassila.
se representa en
RDF/XML: <rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator>Ora Lassila</s:Creator>
</rdf:Description>
</rdf:RDF>
Aquí el prefijo del namespace 's' se refiere a un prefijo específico elegido por
el autor de esta expresión RDF y definido en una declaración XML del namespace
como ésta:
xmlns:s="http://description.org/schema/"
Esta declaración del namespace podría incluirse normalmente
como un atributo XML en el elemento rdf:RDF pero también
puede incluirse con un elemento Description específico o incluso
una expresión propertyElt concreta. El URI del nombre del namespace, en la
declaración del namespace, es un identificador único universal para un esquema
particular que la persona que define los metadatos [este autor de los
metadatos] utiliza para definir el uso de la propiedad Creator. Otros esquemas
pueden definir igualmente la propiedad denominada Creator y las dos
propiedades se diferenciarán gracias a sus identificadores de esquema. Nótese
también que un esquema normalmente define también varias propiedades; una única
declaración de namespace será suficiente para crear un amplio vocabulario de
propiedades que podrán usarse.
El documento XML completo que contiene la descripción citada anteriormente,
podría ser:
<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://description.org/schema/">
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator>Ora Lassila</s:Creator>
</rdf:Description>
</rdf:RDF>
Utilizando la sintaxis de namespace definida por defecto en [NAMESPACES] para el
propio namespace de RDF, este documento podría expresarse también así:
<?xml version="1.0"?>
<RDF
xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://description.org/schema/">
<Description about="http://www.w3.org/Home/Lassila">
<s:Creator>Ora Lassila</s:Creator>
</Description>
</RDF>
Además, la declaración de namespace puede asociarse con un
elemento Description concreto e incluso un elemento
propertyElt particular como en este ejemplo:
<?xml version="1.0"?>
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<Description about="http://www.w3.org/Home/Lassila">
<s:Creator xmlns:s="http://description.org/schema/">Ora Lassila</s:Creator>
</Description>
</RDF>
Como las declaraciones de namespace XML pueden
anidarse, el ejemplo anterior puede además condersarse así: <?xml version="1.0"?>
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<Description about="http://www.w3.org/Home/Lassila">
<Creator xmlns="http://description.org/schema/">Ora Lassila</Creator>
</Description>
</RDF>
Sin embargo, las expresiones demasiado condensadas como ésta
deben evitarse cuando la codificación RDF/XML se escribe a mano o se edita en un
editor de texto plano. Aunque no son ambiguas, la posibilidad de error es mayor
que si se los prefijos explícitos se usan de manera consistente. Nótese que un
fragmento RDF/XML que se realiza para insertarse en otro documento debe declarar
todos los namespaces que utiliza de tal forma que sea completamente
independiente. Para una mejor legibilidad, los ejemplos utilizados en el resto
de esta sección omiten la declaración del namespace para no complicar
[oscurecer] los aspectos específicos que se ilustran.
2.2.2. Sintaxis abreviada básica
Aunque la sintaxis serializada muestra la estructura de un
modelo RDF más claro, normalmente es mejor utilizar una forma XML más compacta.
Esto se lleva a cabo a través de la sintaxis abraviada de RDF. Como valor
añadido, la sintaxis abreviada permite a los documentos seguir DTDs de XML bien
estructuradas que se interpretan como modelos RDF.
Se definen tres formas de abreviación para la sintaxis básica
serializada. La primera se puede utilizar para propiedades no repetidas dentro
de un elemento Description donde los valores de dichar
propiedades son literales. En este caso, las propiedades se pueden expresar como
atributos XML del elemento Description. El ejemplo anterior se
convierte pues en:
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila"
s:Creator="Ora Lassila" />
</rdf:RDF>
Nótese que desde que el elemento Description no tiene
otro contenido desde que la propiedad Creator se escribe en forma de atributo
XML, la sintaxis de elemento vación de XML se emplea para omitir la etiqueta
final de Description.
Aquí se presenta otro ejemplo del uso de esta misma forma abreviada:
<rdf:RDF>
<rdf:Description about="http://www.w3.org">
<s:Publisher>World Wide Web Consortium</s:Publisher>
<s:Title>W3C Home Page</s:Title>
<s:Date>1998-10-03T02:27</s:Date>
</rdf:Description>
</rdf:RDF>
equivalente para los fines de RDF
a:
<rdf:RDF>
<rdf:Description about="http://www.w3.org"
s:Publisher="World Wide Web Consortium"
s:Title="W3C Home Page"
s:Date="1998-10-03T02:27"/>
</rdf:RDF>
Nótese que a pesar de que estas dos expresiones RDF son
equivalentes, deben tratarse de forma diferente por distintos motores de
procesamiento. En particular, si estas dos expresiones estuviesen embebidas en
un documento HTML el comportamiento por defecto de un navegador que no reconozca
RDF sería presentar los valores de las propiedades en el primer caso y en el
segundo caso debería presentarse de forma no textual (o al menos un carácter de
espacio en blanco).
La segunda forma abreviada trabaja sobre elementos
Description. Esta forma abreviada puede emplearse para
sentencias específicas donde el objeto de la declaración es otro recurso y el
valor de cualquier propiedad dada "in-line" para este segundo recurso son
strings (cadenas de caracteres manipuladas como grupo). En este caso se usa una
transformación similar de elementos XML que se nombran como atributos XML: las
propiedades del recurso en el elemento Description anidado
puede escribirse como atributos XML del elemento propertyElt en el
que se comprende Description.
La frase del segundo ejemplo de la Sección 2.1.1
El individuo al que se refiere el
identificador de empleado id 85740 se llama Ora Lassila y tiene la
dirección de correo lassila@w3.org. Ese individuo creó el recurso
http://www.w3.org/Home/Lassila
se escribe en RDF/XML
utilizando la forma serializada explícita como: <rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator rdf:resource="http://www.w3.org/staffId/85740"/>
</rdf:Description>
<rdf:Description about="http://www.w3.org/staffId/85740">
<v:Name>Ora Lassila</v:Name>
<v:Email>lassila@w3.org</v:Email>
</rdf:Description>
</rdf:RDF>
De esta forma se evidencia al lector que se están describiendo
dos recursos separados pero lo que está menos claro es que el segundo recurso se
use en la primera descripción. Esta misma expresión podría escribirse de la
forma que se señala a continuación para mostrar esta relación más obvia. Nótese
que para la máquina, no habría diferencia:
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator>
<rdf:Description about="http://www.w3.org/staffId/85740">
<v:Name>Ora Lassila</v:Name>
<v:Email>lassila@w3.org</v:Email>
</rdf:Description>
</s:Creator>
</rdf:Description>
</rdf:RDF>
Utilizando esta segunda sintaxis abreviada, el elemento
interior Description y las expresiones de las propiedades que
contiene pueden escribirse como atributos del elemento
Creatort:
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator rdf:resource="http://www.w3.org/staffId/85740"
v:Name="Ora Lassila"
v:Email="lassila@w3.org" />
</rdf:Description>
</rdf:RDF>
Cuando usamos esta forma abreviada, el atributo
about del elemento anidado Description se
convierte en un atributo de resource en el elemento
propertyElt, de igual forma que el recurso designado por el URI es en
ambos casos el valor de la propiedad Creator. Es simplemente una cuestión
de preferencia [de la persona que asigna los metadatos] la elección de una de
las tres formas señaladas que se usará en la fuente RDF. Todas producen los
mismos modelos RDF internos.
Nota: El lector observador que haya
analizado el resto de este documento comprobará que existen algunas relaciones
adicionales representadas por el elemento Description para
conservar la agrupación sintáctica específica de las sentencias [o
declaraciones]. Por lo tanto las tres formas señaladas son ligeramente
diferentes aunque sin importancia para la discusión que se plantea en esta
sección. Estas diferencias serán importantes sólo cuando se realicen
sentencias de alto nivel como se describe en la Sección
4.
La tercera forma de sintaxis abreviada básica se aplica a el
caso común de un elemento Description que contenga un propiedad
type (para el significado de type, ver Section 4.1). En este caso,
el tipo de recurso definido en el esquema que corresponde al valor de la
propiedad type puede utilizarse directamente como un nombre de
elemento. Por ejemplo, utilizando el fragmento RDF anterior si queremos añadir
que el recurso http://www.w3.org/staffId/85740 representa una instancia [objeto
específico de la categoría] de una persona, podríamos escribirlo en una sintaxis
serializada completa, así:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:s="http://description.org/schema/">
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator>
<rdf:Description about="http://www.w3.org/staffId/85740">
<rdf:type resource="http://description.org/schema/Person"/>
<v:Name>Ora Lassila</v:Name>
<v:Email>lassila@w3.org</v:Email>
</rdf:Description>
</s:Creator>
</rdf:Description>
</rdf:RDF>
y utilizando la tercera forma abreviada,
así: <rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila">
<s:Creator>
<s:Person about="http://www.w3.org/staffId/85740">
<v:Name>Ora Lassila</v:Name>
<v:Email>lassila@w3.org</v:Email>
</s:Person>
</s:Creator>
</rdf:Description>
</rdf:RDF>
La EBNF para la sintaxis abreviada sustituye las producciones
[2] y [6] de la grámatica para la sintaxis serializa básica, de la siguiente
forma:
[2a] description ::= '<rdf:Description' idAboutAttr? propAttr* '/>'
| '<rdf:Description' idAboutAttr? propAttr* '>'
propertyElt* '</rdf:Description>'
| typedNode
[6a] propertyElt ::= '<' propName '>' value '</' propName '>'
| '<' propName resourceAttr? propAttr* '/>'
[16] propAttr ::= propName '="' string '"'
(with embedded quotes escaped)
[17] typedNode ::= '<' typeName idAboutAttr? propAttr* '/>'
| '<' typeName idAboutAttr? propAttr* '>'
property* '</' typeName '>'
2.2.3. Esquemas y Namespaces
Cuando escribimos una frase en lenguaje natural utilizamos
palabras que encierran la intención de transmitir un significado inequívoco. Ese
significado es fundamental para entender el enunciado y, en el caso de
aplicaciones de RDF es crucial para establecer que el procesamiento correcto se
dé como se esperaba. Es muy importante que tanto el escritor como el lector de
una sentencia [declaración] entiendan el mismo significado para los términos
utilizados, tales como Creator, approvedBy, Copyright, etc. o resultará
una gran confusión. En un medio a escala global como es le World Wide Web no es
suficiente confiar en el entendimiento cultural de conceptos tales como la
"autoría de una página" ["creatorship"]; conviene ser lo más preciso
posible.
En RDF el significado se expresa a través de un esquema.
Podemos pensar en un esquema como en una especie de diccionario. Un esquema
define los términos que se utilizarán en una sentencia [declaración] RDF y le
otorgará significados específicos. Con RDF pueden utilizar una gran variedad de
formas de esquema, incluyendo una forma específica definida en un documento
aparte [RDFSchema] que
tiene algunas características específicas para ayudar a la automatización de
tareas usando RDF.
Un esquema es un sitio donde se documentan [se explican] las
definiciones y restricciones de uso de las propiedades. Para evitar confusiones
entre definiciones independientes --y posiblemente conflictivas-- del mismo
término, RDF utiliza la facilidad de los namespace de XML. Los namespaces
["espacios de nombre"] son simplemente una forma de asociar el uso específico de
una palabra en el contexto del diccionario (esquema) en que se puede encontrar
una definición determinada. En RDF, cada predicado utilizado en una sentencia
[declaración] debe ser identificado con un sólo namespace, o esquema. Sin
embargo un elemento Description puede contener sentencias con
predicados de varios esquemas. Ejemplos donde las descripciones RDF utilizan más
de un esquema aparecen en la Sección 7.
2.3. Valores de propiedad cualificados
Muchas veces el valor de una propiedad es algo que tiene
información contextual adicional que se considera "parte de" dicho valor. En
otras palabras, es necesario cualificar [o distinguir] los valores de las
propiedades. Ejemplos de tales distinciones incluyen la denominación de una
unidad de medida, un vocabulario restringido particular, u otros comentarios.
Para algunos usos resulta apropiado utilizar el valor de la propiedad sin
identificadores o calificadores. Por ejemplo, en la frase "
el precio de aquel lápiz es 75 centavos de dólar" en la mayoría de los
casos es suficiente decir simplemente "el precio de aquél
lápiz es 75".
En el modelo RDF un valor de propiedad cualificada es
simplemente otra instancia de un valor estructurado. El objeto de la sentencia
original es este valor estructurado y los calificadores [identificadores] son
más propiedades de dicho recurso. El principal valor que se cualificará se dará
como el valor de la propiedad value del recurso en cuestión. Para
un ejemplo del uso de la propiedad value, ver Section 7.3. Relaciones
no-binarias.
3. Contenedores
Normalmente es necesario referirse a una colección de recursos,
por ejemplo, para expresar que un trabajo se creó por más de una persona, o para
enumerar los estudiantes de un curso, o los módulos de un software en un
paquete. Los contenedores RDF se usan para mantener tales listas de recursos o
literales.
3.1. Modelo Contenedor
RDF define tres tipos de objetos
contenedores:
| Bag |
Una lista desordenada de recursos o literales. Los
Bags se utilizan para indicar que una propiedad tiene
múltiples valores y que no es significativo el orden en que se den
tales valores
Bag podría usarse para dar una lista de
números de parte donde el orden de procesamiento de las partes no tiene
importancia. Se permite duplicar valores. |
| Sequence |
Una lista ordenada de recursos o literales.
Sequence se usa para manifestar que una propiedad tiene
múltiples valores y que el orden de los valores es significativo.
Sequence podría usarse, por ejemplo para conservar un orden
alfabético de valores. Se permite duplicar valores. |
| Alternative |
Una lista de recursos o literales que representan
alternativas para un valor (individual) de una propiedad.
Alternative podría usarse para proporcionar una lengua alternativa
de traducción para el título de un trabajo, o para proporcionar un alista
de mirrors de Internet en los que se podría encontrar un recurso. Una
aplicación que utiliza una propiedad cuyo valor es una colección
alternativa, sabe que se puede elegir como correcto uno cualquiera
de los ítems en la lista. |
Nota: Las definiciones de
Bag y Sequence permiten explícitamente duplicar
valores. RDF no define un concepto puntual de Set, que podría
ser un Bag sin duplicados, porque la esencia de RDF no impone un
mecanismo de ejecución en el caso de que se violen estas restricciones. En un
trabajo futuro en torno a la esencia de RDF pueden definirse tales
facilidades.
Para representar colecciones de recursos, RDF utiliza un
recurso adicional que identifica la colección específica (una instancia [objeto
específico de una categoría] de una colección, en la terminología del modelado
de objetos). Este recurso pude declararse como una instancia de uno de los tipos
objetos contenedores definidos arriba. La propiedad type, definida
a continuación, se utiliza para hacer esta declaración. La relación de
pertenencia entre estos recursos contenedores y los recursos que pertenecen a la
colección se defina por un conjunto de propiedades definidas expresamente con
este propósito. Estas propiedades [de filiación] se denominan simplemente
"_1", "_2", "_3", etc. Los recursos contenedores pueden
tener otras propiedades añadidas a las propiedades de pertenencia. y la
propiedad type. Cualquiera de tales sentencias adicionales
describe el contenedor, ver Sección
3.3, Referentes Distributivos, para la profundizar en sentencias sobre cada
uno de los miembros.
Un uso común de los contenedores es como valor de una
propiedad. Cuando se usa de esta forma, la sentencia tiene, a pesar de todo, un
único objeto de declaración, sin tener en cuenta el número de miembros que tenga
en el contenedor; el propio recurso contenedor es entonces, el objeto de la
sentencia [o declaración].
Por ejemplo, para representar la sentencia.
Los estudiantes que cursan la
asignatura 6.001 son Amy, Tim, John, Mary, y Sue.
el
modelo RDF es
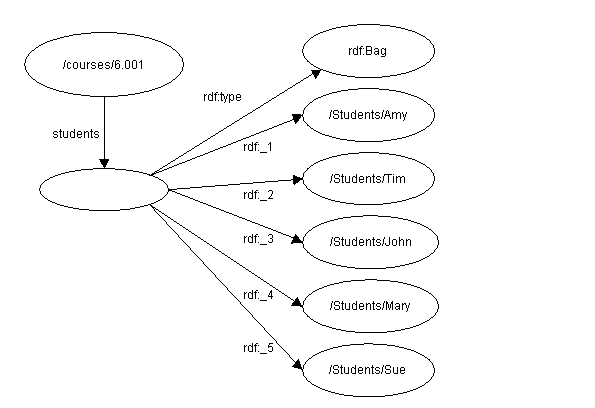 D
Figura 4: Contenedor Bag simple
D
Figura 4: Contenedor Bag simple
Los contenedores Bag no son equivalentes para
propiedades repetidas del mismo tipo; ver Sección
3.5. para profundizar en la diferencia. Los autores decidirán en cada caso
el principio en que una (propiedad repetida de la sentencia o un Bag) es más
apropiado de usar.
La frase:
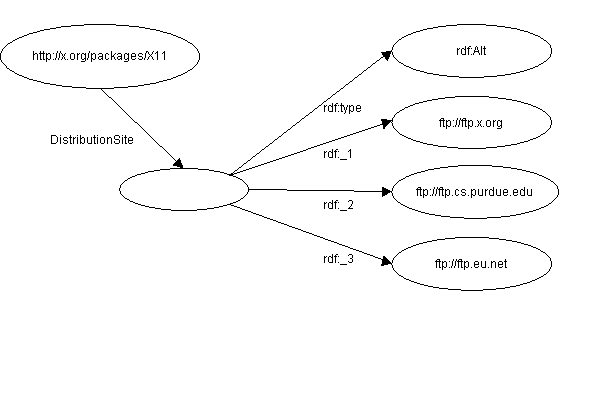
El código fuente para X11 puede encontrarse
en ftp.x.org, ftp.cs.purdue.edu o en ftp.eu.net.
se
modela en RDF así:
 D
Figura 5: Contenedor Alternative simple
D
Figura 5: Contenedor Alternative simple
Se utilizan con frecuencia contenedores
alternativos en combinación con el lenguaje de marcado. Un trabajo cuyo título
se ha traducido en varias lenguas podría tener su propiedad Title apuntandoa un
contenedor alternativo que mantenga cada una de las variantes
idiomáticas.
3.2. Sintaxis de contenedores
La sintaxis de un contenedor RDF toma la
forma: [18] container ::= sequence | bag | alternative
[19] sequence ::= '<rdf:Seq' idAttr? '>' member* '</rdf:Seq>'
[20] bag ::= '<rdf:Bag' idAttr? '>' member* '</rdf:Bag>'
[21] alternative ::= '<rdf:Alt' idAttr? '>' member+ '</rdf:Alt>'
[22] member ::= referencedItem | inlineItem
[23] referencedItem ::= '<rdf:li' resourceAttr '/>'
[24] inlineItem ::= '<rdf:li>' value '</rdf:li>'
Los
contenedores pueden usarse en todos los casos en que se permita un elemento
Description: [1a] RDF ::= '<rdf:RDF>' obj* '</rdf:RDF>'
[8a] value ::= obj | string
[25] obj ::= description | container
Nótese como RDF/XML utiliza li como elemento de
conveniencia para evitar que tenga cada miembro un número explícito. El elemento
li asigna las propiedades _1,
_2, y así si es necesario. El nombre del elemento "li
se eligió para que fuera mnemotécnico con el término "list item" del HTML.
Se necesita un cotenedor Alt para tener al
menos un miembro. Este miembro se identificará con la propiedad
_1 y es el valor por defecto o preferido.
Nota: La especificación del esquema
RDF [RDFSCHEMA] también
define un mecanismo para declarar subclases adicionales de estos tipos de
contenedores, el cuyo caso la producción 18] se extiende a la inclusión de
nombres de estas subclases definidas. También existe una sintaxis para
escribir valores literales en forma de atributo; ver la gramática completa en
la Sección
6.
3.2.1. Ejemplos
El modelo para la frase
Los estudiantes que cursan la
asignatura 6.001 son Amy, Tim, John, Mary, y Sue.
se
escribe en RDF/XML así <rdf:RDF>
<rdf:Description about="http://mycollege.edu/courses/6.001">
<s:students>
<rdf:Bag>
<rdf:li resource="http://mycollege.edu/students/Amy"/>
<rdf:li resource="http://mycollege.edu/students/Tim"/>
<rdf:li resource="http://mycollege.edu/students/John"/>
<rdf:li resource="http://mycollege.edu/students/Mary"/>
<rdf:li resource="http://mycollege.edu/students/Sue"/>
</rdf:Bag>
</s:students>
</rdf:Description>
</rdf:RDF>
En este caso, teniendo en cuenta que el valor de la propiedad
"students", se expresa como un Bag el orden dado no tiene significado el orden
dado aquí para el URI de cada estudiante.
El modelo para la frase
El código fuente para X11 puede encontrarse
en ftp.x.org, ftp.cs.purdue.edu o en ftp.eu.net.
se
escribe en RDF/XML así: <rdf:RDF>
<rdf:Description about="http://x.org/packages/X11">
<s:DistributionSite>
<rdf:Alt>
<rdf:li resource="ftp://ftp.x.org"/>
<rdf:li resource="ftp://ftp.cs.purdue.edu"/>
<rdf:li resource="ftp://ftp.eu.net"/>
</rdf:Alt>
</s:DistributionSite>
</rdf:Description>
</rdf:RDF>
Aquí, cualquiera de los ítems enumerados en el valor del
contenedor para "DistributionSite" es un valor aceptable sin tener en cuenta a
los otros ítems.
3.3. Referentes
distributivos: sentencias sobre miembros de un contenedor
Las estructuras de contenedores han dado lugar a una cuestión
relativa a las sentencias [o declaraciones]: cuando una sentencia se hace
refiriéndose a una colección, ¿qué "cosa" describe la sentencia? O en otras
palabras, ¿a qué objetos se refiere la sentencia?¿La sentencia describe al
propio contenedor o describe a los miembros de dicho contenedor? El objeto
descrito (en la sintaxis XML indicada por el atributo about) se
denomina en RDF referente.
El siguiente ejemplo:
<rdf:Bag ID="pages">
<rdf:li resource="http://foo.org/foo.html" />
<rdf:li resource="http://bar.org/bar.html" />
</rdf:Bag>
<rdf:Description about="#pages">
<s:Creator>Ora Lassila</s:Creator>
</rdf:Description>
expresa que "Ora Lassila" es el creador de las páginas Bag. Sin
embargo no dice nada sobre las páginas individuales, de los miembros del Bag. El
referente del elemento Description es el contenedor (Bag), no
sus miembros. Alguna vez, a alguien se le podría ocurrir escribir una sentencia
sobre cada uno de los objetos contenidos individualmente, en vez del propio
contenedor. Para expresar que "Ora Lassila" es el creador de cada una de las
páginas, se necesita un tipo distinto de referente, uno que distribuya a
los miembros del contenedor. El referente en RDF se expresa usando el atributo
aboutEach:
[3a] idAboutAttr ::= idAttr | aboutAttr | aboutEachAttr
[26] aboutEachAttr ::= 'aboutEach="' URI-reference '"'
Como
ejemplo, si escribiéramos <rdf:Description aboutEach="#pages">
<s:Creator>Ora Lassila</s:Creator>
</rdf:Description>
obtendríamos el significado deseado. Llamaríamos al nuevo tipo
de referente un referente distributivo. Los referentes distributivos nos
permiten "compartir estructura" en un RDF Description. Por
ejemplo, cuando escribimos varias Descriptions que todas tienen
un número común de partes de sentencia (predicados y objetos) las partes comunes
pueden compartirse entre todos los [elementos] Descriptions,
dando, posiblemente, como resultado metadatos que se mantienen mejor y que
ocupan menos espacio. El valor de un atributo aboutEach debe ser
un contenedor. Usar un referente distributivo en un contenedor es lo mismo que
hacer todas las sentencias sobre cada uno de los miembros de forma
individual.
No se ha definido una representación gráfica explícita de los
referentes distributivos. En cambio, en términos de elaboración de sentencias,
los referentes distributivos se expanden en sentencias individuales sobre los
miembros del contenedor (internamente, las implementaciones son libres de
retener información sobre los referentes distributivos --para ahorrar espacio,
por ejemplo-- mientras cualquier función de interrogación trabaja como si todas
las sentencias se hiciesen individualmente). Así, en relación con los recursos
"foo" y "bar", el ejemplo anterior es equivalente a
<rdf:Description about="http://foo.org/foo.html">
<s:Creator>Ora Lassila</s:Creator>
</rdf:Description>
<rdf:Description about="http://bar.org/bar.html">
<s:Creator>Ora Lassila</s:Creator>
</rdf:Description>
3.4. Contenedores definidos por un patrón URI
Un uso muy frecuente de los metadatos es hacer sentencias sobre
"todas las páginas en mi sitio Web", o "todas las páginas en esta parte de mi
sitio Web". En muchos casos es poco práctico e incluso no recomendable intentar
enumerar cada uno de los recursos explícitamente e identificarlo como miembro de
un contenedor. Por consiguiente RDF tiene un segundo tipo de referente
distributivo. El segundo tipo de referente distributivo es una sintaxis
abreviada [taquigráfica] que representa una instancia de un Bag cuyos miembros
son, por definición, todos los recursos cuyos identificadores comienzan con un
string [serie de caracteres manipulados como un grupo] específico:
[26a] aboutEachAttr ::= 'aboutEach="' URI-reference '"'
| 'aboutEachPrefix="' string '"'
El atributo aboutEachPrefix pone de
manifiesto que hay un Bag cuyos miembros son recursos de los que, as su vez, los
identificadores de recursos resueltos totalmente comienzan con el string de
caracteres dado como el valor del atributo. La sentencia en una
Description que tiene el atributo
aboutEachPrefix se refiere a cada uno de los miembros de ese
contenedor.
Por ejemplo, si los dos recursos http://foo.org/doc/page1 y
http://foo.org/doc/page2 existen, podemos decir que cada uno de ellos tiene una
propiedad de copyright, escribiendo:
<rdf:Description aboutEachPrefix="http://foo.org/doc">
<s:Copyright>© 1998, The Foo Organization</s:Copyright>
</rdf:Description>
Si estos son los dos únicos recursos cuyas URIs comienzan con
tal string, la [expresión] anterior es equivalente a estas dos
alternativas:
<rdf:Description about="http://foo.org/doc/page1">
<s:Copyright>© 1998, The Foo Organization</s:Copyright>
</rdf:Description>
<rdf:Description about="http://foo.org/doc/page2">
<s:Copyright>© 1998, The Foo Organization</s:Copyright>
</rdf:Description>
y <rdf:Description aboutEach="#docpages">
<s:Copyright>© 1998, The Foo Organization</s:Copyright>
</rdf:Description>
<rdf:Bag ID="docpages">
<rdf:li resource="http://foo.org/doc/page1"/>
<rdf:li resource="http://foo.org/doc/page2"/>
</rdf:Bag>
3.5. Contenedores versus propiedades
repetidas
Un recurso puede tener múltiples sentencias con el mismo
predicado( es decir, que usan la misma propiedad). Esto no es lo mismo que tener
una única sentencias cuyo objeto es un contenedor que contiene diversos
miembros. La elección de cuál usar en una circunstancia particular está en parte
determinado por la persona que diseña el esquema y en parte por la persona que
escribe la sentencia RDF específica.
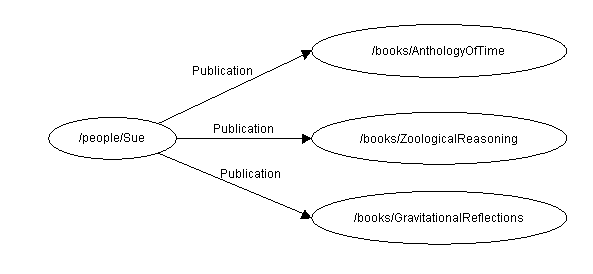
Consideremos como un ejemplo
la relación entre una escritora y sus publicaciones. Podemos tener la frase:
Sue ha escrito "Anthology of Time",
"Zoological Reasoning", "Gravitational Reflections".
Es
decir, hay tres recursos cada uno de los cuales se escribió de forma
independiente por el mismo escritor.
 D
Figura 6: Propiedad repetida
D
Figura 6: Propiedad repetida
En este ejemplo no hay una relación manifiesta entre las publicaciones, a
parte de que fue la misma persona quien las escribió.
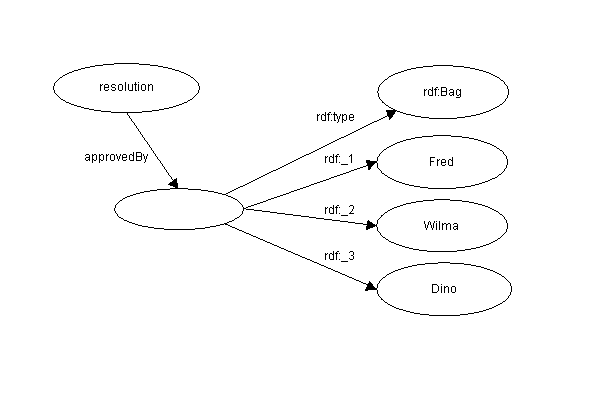
Por otra parte, la frase
El comité de Fred, Wilma, and Dino aprobó
la resolución.
dice que los tres miembros del comité de manera general votaron
de una cierta forma, no es necesario afirmar que cada miembro del comité votó en
favor de la cláusula. Sería incorrecto modelar esta sentencia como tres
sentencias separadas de tipo "approvedBy" una para cada miembro del
comité, para afirmar el voto de cada miembro individual. Mejor dicho, es mejor
modelarlo como una única sentencia de tipo "approvedBy" cuyo objeto es un
Bag que contiene las identidades de los miembros del comité.
 D
Figura 7: Utilización del contenedor Bag para indicar una opinión
colectiva
D
Figura 7: Utilización del contenedor Bag para indicar una opinión
colectiva
La elección de qué representación usar, el contenedor Bag
o propiedades repetidas, viene determinada por la persona que crea [asigna]
los metadatos después de considerar el esquema. Si, p. ej., en el ejemplo
anterior de las publicaciones quisiéramos decir que esas eran el conjunto
completo de publicaciones, el esquema debería incluir una propiedad denominada
publications. El valor de la propiedad publications
sería un Bag que enumerara todos los trabajos de la escritora
Sue.
4. Declaraciones sobre declaraciones [sentencias
sobre sentencias]
Además de hacer sentencias sobre los recursos Web, RDF puede
usarse para crear sentencias sobre otras declaraciones RDF; nos referiremos a
éstas como sentencias de alto nivel [higher-order statements]. Para
realizar declaraciones sobre otras declaraciones, tenemos que construir un
modelo de la sentencia original; este modelo es un nuevo recurso al que podemos
anexar propiedades adicionales.
4.1. Modelado de sentencias
Las sentencias se hacen sobre los recursos. Un modelo de una
sentencia es el recurso que necesitamos para poder hacer una nueva declaración
(una sentencia de alto nivel) sobre la declaración modelada.
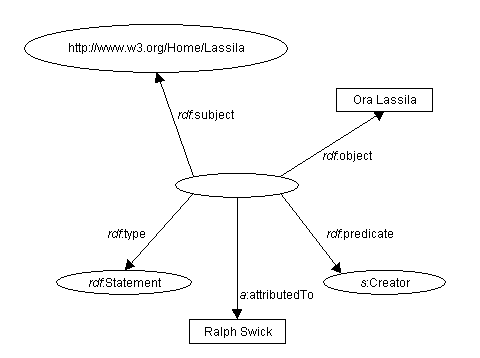
Por ejemplo, consideremos la frase:
Ora Lassila es el creador [autor] del
recurso http://www.w3.org/Home/Lassila.
RDF estimaría
esta sentencia como un hecho. Si, en lugar de eso, escribimos la frase:
Ralph Swick dice que Ora Lassila el creador
[autor] del recurso http://www.w3.org/Home/Lassila.
no hemos dicho nada sobre el recurso
http://www.w3.org/Home/Lassila; en cambio, hemos expresado el hecho sobre la
afirmación que hizo Ralph. Para expresar este hecho en RDF, tenemos que modelar
la declaración original como un recurso con cuatro propiedades. Este proceso se
denomina formalmente "reification" [transformación de algo abstracto en
concreto] en el contexto de la Representación del Conocimiento. Un modelo de
sentencia se denomina "reified statement" [sentencia transformada de lo
abstracto a lo concreto].
RDF define las siguientes propiedades para modelar sentencias:
|
subject
[sujeto] |
La propiedad subject identifica el recurso que
describe la sentencia modelada; es decir, el valor de la propiedad
subject es el recurso sobre el cual se hizo la sentencia original
(en nuestro ejemplo, http://www.w3.org/Home/Lassila). |
|
predicate
[predicado] |
La propiedad predicate identifica la propiedad
original en la declaración modelada. El valor de la propiedad
predica es un
recurso que representa la propiedad específica en la sentencia original
(en nuestro ejemplo, el creador creator). |
|
object
[objeto] |
La propiedad object identifica el valor de la
propiedad en la sentencia modelada. El valor de la propiedad object
es el objeto en la sentencia original (en nuestro ejemplo "Ora
Lassila"). |
|
type
[tipo] |
El valor de la propiedad type describe el tipo del
nuevo recurso. Todas las sentencias transformadas [de lo abstracto a lo
concreto] son instancias de RDF: sentencias; es decir tienen una propiedad
type cuyo objeto es RDF:sentencia. La propiedad type se usa
más comúnmente también para declarar el tipo del recurso, como se mostró
en la Sección 3, "Contenedores". |
Un nuevo recurso con las cuatro propiedades anteriores
representa la sentencia original y puede tanto usarse como objeto de otras
declaraciones como tener una sentencia adicional sobre él. El recurso con estas
cuatro propiedades no es un substituto de la sentencia original, es un modelo de
la declaración. Una sentencia [declaración] y sus correspondientes sentencias
transformadas [de lo abstracto a lo concreto, reified] existe
independientemente sin las otras. La representación gráfica RDF se presenta para
contener el hecho de la sentencia si y sólo si dicha sentencia se presenta en
forma gráfica, sin considerar si la sentencia correspondiente transformada está
presente.
Para modelar el ejemplo anterior, podemos adjuntar otra
propiedad a la sentencia transformada (es decir, "attributedTo") con un
valor apropiado (en este caso "Ralph Swick"). Utilizando la sintaxis de nivel
básico RDF/XML, podría escribirse así:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:a="http://description.org/schema/">
<rdf:Description>
<rdf:subject resource="http://www.w3.org/Home/Lassila" />
<rdf:predicate resource="http://description.org/schema/Creator" />
<rdf:object>Ora Lassila</rdf:object>
<rdf:type resource="http://www.w3.org/1999/02/22-rdf-syntax-ns#Statement" />
<a:attributedTo>Ralph Swick</a:attributedTo>
</rdf:Description>
</rdf:RDF>
La figura 8 representa esto gráficamente. Sintácticamente es
más bien poco concisa [o poco prolija]; en la Sección
4.2.
presentamos unas abreviaturas [taquigrafía] para hacer sentencias sobre
sentencias [declaraciones sobre declaraciones RDF]
 D
Figura 8: Representación de una sentencia transformada de lo abastracto
a lo concreto
D
Figura 8: Representación de una sentencia transformada de lo abastracto
a lo concreto
La reification [transformación de algo abstracto en algo
concreto] se necesita también para representar explícitamente en el modelo la
sentencia de agrupación implícita en el elemento Description. El
modelo gráfico RDF no necesita una construcción especial para los elementos
Description; dado que los Descriptions son en
realidad colecciones de sentencias, se usa un contenedor Bag
para indicar que un conjunto de sentencias que provienen del mismo elemento
(sintáctico) Description. Cada sentencia dentro de un
Description se transforma [reified] y cada una de las sentencias
transformadas es miembro del Bag que representa dicha
Description. Como ejemplo de esto, este fragmento RDF:
<rdf:RDF>
<rdf:Description about="http://www.w3.org/Home/Lassila" bagID="D_001">
<s:Creator>Ora Lassila</s:Creator>
<s:Title>Ora's Home Page</s:Title>
</rdf:Description>
</rdf:RDF>
resultaría en el gráfico de la figura 9.
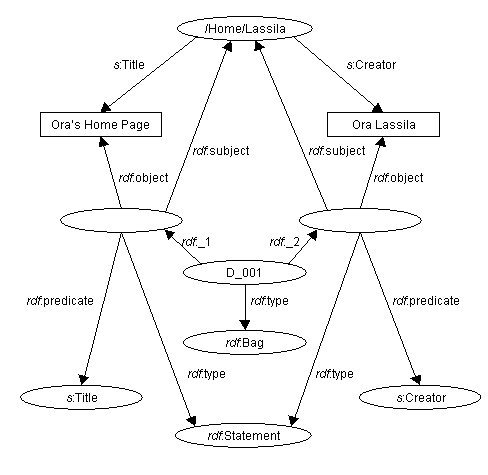 D
Figura 9: Uso de Bag para representar la sentencia
agrupada
D
Figura 9: Uso de Bag para representar la sentencia
agrupada
Nótese el nuevo atributo bagID. Este atributo especifica el
recurso id del recurso contenedor:
[2b] description ::= '<rdf:Description' idAboutAttr? bagIDAttr? propAttr* '/>'
| '<rdf:Description' idAboutAttr? bagIDAttr? propAttr* '>'
propertyElt* '</rdf:Description>'
[27] bagIDAttr ::= 'bagID="' IDsymbol '"'
BagID e ID no deben
confundirse. ID especifica el identificador de un recurso
in-line cuyas propiedades se detallan más ampliamente en la descripción
[elemento Description]. BagID especifica la identificación del
recurso contenedor cuyos miembros son sentencias transformadas [de lo abstracto
a lo concreto] sobre otro recurso. Un elemento Description puede
tener ambos atributos ID y bagID.
4.2. Abreviatura sintáctica para sentencias
sobres sentencias
Dado que añadir un bagID a un elemento
Description conlleva incluir en el modelo un Bag de la sentencia
transformada [de lo abstracto a lo concreto] de Description,
podemos usar esta como una abreviatura sintáctica cuando hagamos sentencias
sobre sentencias. Por ejemplo, se queremos decir que Ralph afirma que Ora es el
creador de http://www.w3.org/Home/Lassila y que el título de dicho recurso es
"Ora's Home Page", simplemente podemos añadir al ejemplo anterior:
<rdf:Description aboutEach="#D_001">
<a:attributedTo>Ralph Swick</a:attributedTo>
</rdf:Description>
Nótese que este ejemplo de la taquigrafía [abreviatura] incluye
hechos adicionales en el modelo no representados en el ejemplo de la figura 8.
El uso de esta abreviatura expresa hechos sobre las afirmaciones de Ralph y
también hechos sobre la home page de Ora.
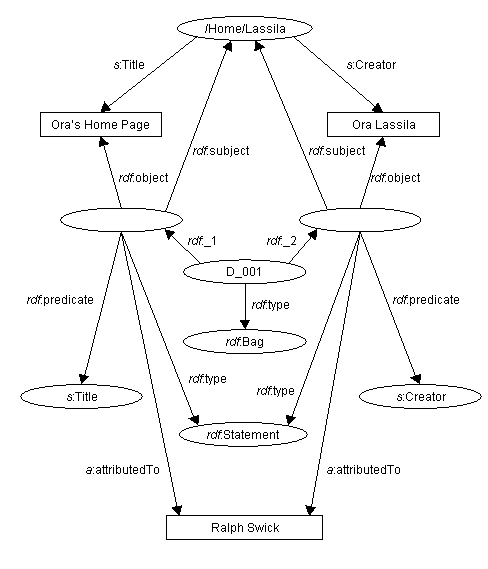 D
Figura 10: Representación de sentencias sobre sentencias
D
Figura 10: Representación de sentencias sobre sentencias
Se remite al lector a la Sección
5 ("Modelo Formal") de esta especificación para un tratamiento formal de las
sentencias de alto nivel [higher-order statements] y la transformación de
lo abstracto a lo concreto [reification].
5. Modelo formal para RDF
Esta especificación presenta tres representaciones del modelo
de datos; como 3-tuplas (triples), como gráfico, y en XML. Estas
representaciones tienen un significado equivalente. El mapeo entre las
representaciones que se utilizan en esta especificación no tienen pretenden de
forzar de ninguna manera la representación interna usada en la
implementación.
El modelo de datos de RDF se define formalmente como sigue:
- Hay un conjunto denominado Recursos [Resources].
- Hay un conjunto denominado Literales [Literals].
- Hay un subconjunto Recursos [Resources] denominado
Propiedades [Properties].
- Hay un conjunto denominado Sentencias
[Statements], cada elemento de los cuales es un triple de la forma.
{pred, sub, obj}
Donde pred es una propiedad (miembro de Properties),
sub es un recurso (miembro de Resources), y obj
puede ser tanto un recurso como un literal (miembro de
Literals). |
Podemos ver un conjunto de sentencias (miembros de
Statements) como un gráfico directamente etiquetado: cada recurso y
literal es un vértice, un triple {p, s, o} es un arco de s hasta
o etiquetado por p. Esto se ilustra en la figura 11.
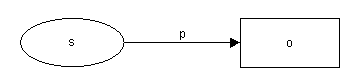 D
Figura 11: Plantilla gráfica de una sentencia simple
D
Figura 11: Plantilla gráfica de una sentencia simple
Esto puede leerse bien como:
o es el valor de p para
s
o como (de derecha a izquierda)
s tiene una propiedad p con un valor
o
o incluso
la p de s es
o
Por ejemplo, la frase:
Ora Lassila es el creador [autor] del
recurso http://www.w3.org/Home/Lassila
se representaría
gráficamente como se presenta a continuación:
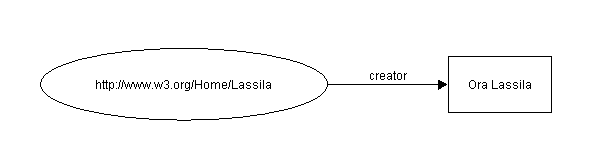 D
Figura 12: Gráfico de una sentencia simpley el triple (miembro
de Statements) correspondiente, sería
D
Figura 12: Gráfico de una sentencia simpley el triple (miembro
de Statements) correspondiente, sería
{creator, [http://www.w3.org/Home/Lassila],
"Ora Lassila"}
La notación [I] denota el recurso
identificado por el URI I y las comillas denotan un literal.
Utilizando los triples, podemos explicar qué sentencias están
transformadas (como se presentó en la Sección 4). Dada una sentencia
{creator, [http://www.w3.org/Home/Lassila], "Ora
Lassila"}
podemos expresar la transformación [reification] de esto
como un nuevo recurso X, así:
{type, [X], [RDF:Statement]}
{predicate, [X], [creator]}
{subject, [X], [http://www.w3.org/Home/Lassila]}
{object, [X], "Ora Lassila"}
Desde el punto de vista de un procesador RDF, los hechos (es
decir, las sentencias o statements) son triples que son miembros de
Statements. Por lo tanto, la sentencia original permanece como un hecho a
pesar de que se transforme [de lo abstracto a lo concreto], dado que el triple
que representa la sentencia original permanece en Statements.
Sencillamente hemos añadido cuatro triples más.
La propiedad denominada "type" se define para proporcionar la
tipografía primigenia. La definición formal de type es:
- Hay un elemento de Propiedades [Properties] conocido como
RDF:type.
- Miembros de sentencias [Statements] de la forma {RDF:type,
sub, obj} pueden satisfacer lo siguiente: sub y obj
son miembros de Recursos [Resources]. [RDFSchema] que
colocan restricciones adicionales en el uso de type.
|
Además, la especificación formal que expresa
la transformación de lo abstracto a lo concreto, es:
- Hay un elemento de Recursos [Resources], no contenido en
Propiedades [Properties], conocido como
RDF:Statement.
- Hay tres elementos en Propiedades [Properties] conocidos como
RDF:predicate, RDF:subject y RDF:object.
- La transformación [Reification] del triple {pred, sub, obj}
de las sentencias es un elemento de Recursos [Resources]
que representa el triple transformado y los elementos s1,
s2, s3, y s4 de Statements así:
s1: {RDF:predicate, r,
pred}
s2:
{RDF:subject, r, subj}
s3: {RDF:object, r, obj}
s4: {RDF:type, r,
[RDF:Statement]} |
El recurso r en la definición anterior se llama
sentencia transformada [reified statement]. Cuando un recurso representa
una sentencia transformada; es decir, que tiene una propiedad RDF:type
con un valor de RDF:Statement, entonces dicho recurso puede tener
exactamente una propiedad RDF:subject, una propiedad RDF:object, y
una propiedad RDF:predicate.
Como se describe en la sección 3, normalmente es necesario
representar una colección de recursos o literales, por ejemplo para declarar que
una propiedad tiene una secuencia ordenada de valores. RDF define tres tipos de
colecciones: listas ordenadas, denominadas Sequences, listas
desordenadas, denominadas Bags, y listas que representan alternativas
para el valor (único) de una propiedad, denominadas
Alternatives.
Formalmente, estos tres tipos de colecciones se definen por:
- Hay tres elementos de Recursos [Resources], no contenidos en
Propiedades [Properties], conocidos como RDF:Seq,
RDF:Bag, y RDF:Alt.
- Hay un subconjunto de Propiedades [Properties] que
corresponden con los ordinales (1, 2, 3, ...) denominados
Ord. Nos referimos a los elementos de Ord
como RDF:_1, RDF:_2, RDF:_3, ...
|
Para representar una colección
c, crear un triple {RDF:type, c,
t} donde t es una de los tres tipos de
colecciones RDF:Seq, RDF:Bag, o RDF:Alt. Los triples restantes {RDF:_1,
c, r1}, ..., {RDF:_n, c, rn},
... apuntan hacia cada uno de los miembros rn de la colección.
Para una colección individual el recurso puede ser como mucho un triple cuyo
predicado es cualquier elemento dado de Ord debe usarse en una
secuencia que comience con RDF:_1. Para recursos que son objetos específicos de
una categoría [instances] del tipo de colección RDF:Alt,
debe ser exactamente un triple cuyo predicado es: RDF:_1 y que es el
valor por defecto para recursos alternativos (esto es, debe tener siempre al
menos una alternativa).
6. Gramática formal para RDF
La BNF [Backus-Naur Form] para RDF se reproduce aquí
para completar las secciones previas. También se da aquí la interpretación
precisa de la gramática formal en términos del modelo formal. Las
características sintácticas heredadas de XML no se reproducen ahora. Esto
incluye todas las restricciones relativas a los documentos bien formados, el uso
del espacio en blanco al rededor de los atributos y el '=', así como el
uso tanto de las comillas simples como dobles en torno a los valores de los
atributos. Esta sección está dirigida a los implementadores que están
construyendo herramientas que lean e interpreten la sintaxis RDF/XML.
A continuación, donde se usen las palabras clave: "SHOULD"
(deber), "MUST" (tener que), y "MUST NOT" (no tener que) se debe interpretar
como se describe en RFC 2119 [RFC2119]. No obstante, para
una mayor legibilidad, estas palabras no aparecen en mayúsculas en esta
especificación.
[6.1] RDF ::= ['<rdf:RDF>'] obj* ['</rdf:RDF>']
[6.2] obj ::= description | container
[6.3] description ::= '<rdf:Description' idAboutAttr? bagIdAttr? propAttr* '/>'
| '<rdf:Description' idAboutAttr? bagIdAttr? propAttr* '>'
propertyElt* '</rdf:Description>'
| typedNode
[6.4] container ::= sequence | bag | alternative
[6.5] idAboutAttr ::= idAttr | aboutAttr | aboutEachAttr
[6.6] idAttr ::= ' ID="' IDsymbol '"'
[6.7] aboutAttr ::= ' about="' URI-reference '"'
[6.8] aboutEachAttr ::= ' aboutEach="' URI-reference '"'
| ' aboutEachPrefix="' string '"'
[6.9] bagIdAttr ::= ' bagID="' IDsymbol '"'
[6.10] propAttr ::= typeAttr
| propName '="' string '"' (with embedded quotes escaped)
[6.11] typeAttr ::= ' type="' URI-reference '"'
[6.12] propertyElt ::= '<' propName idAttr? '>' value '</' propName '>'
| '<' propName idAttr? parseLiteral '>'
literal '</' propName '>'
| '<' propName idAttr? parseResource '>'
propertyElt* '</' propName '>'
| '<' propName idRefAttr? bagIdAttr? propAttr* '/>'
[6.13] typedNode ::= '<' typeName idAboutAttr? bagIdAttr? propAttr* '/>'
| '<' typeName idAboutAttr? bagIdAttr? propAttr* '>'
propertyElt* '</' typeName '>'
[6.14] propName ::= Qname
[6.15] typeName ::= Qname
[6.16] idRefAttr ::= idAttr | resourceAttr
[6.17] value ::= obj | string
[6.18] resourceAttr ::= ' resource="' URI-reference '"'
[6.19] Qname ::= [ NSprefix ':' ] name
[6.20] URI-reference ::= string, interpreted per [URI]
[6.21] IDsymbol ::= (any legal XML name symbol)
[6.22] name ::= (any legal XML name symbol)
[6.23] NSprefix ::= (any legal XML namespace prefix)
[6.24] string ::= (any XML text, with "<", ">", and "&" escaped)
[6.25] sequence ::= '<rdf:Seq' idAttr? '>' member* '</rdf:Seq>'
| '<rdf:Seq' idAttr? memberAttr* '/>'
[6.26] bag ::= '<rdf:Bag' idAttr? '>' member* '</rdf:Bag>'
| '<rdf:Bag' idAttr? memberAttr* '/>'
[6.27] alternative ::= '<rdf:Alt' idAttr? '>' member+ '</rdf:Alt>'
| '<rdf:Alt' idAttr? memberAttr? '/>'
[6.28] member ::= referencedItem | inlineItem
[6.29] referencedItem ::= '<rdf:li' resourceAttr '/>'
[6.30] inlineItem ::= '<rdf:li' '>' value </rdf:li>'
| '<rdf:li' parseLiteral '>' literal </rdf:li>'
| '<rdf:li' parseResource '>' propertyElt* </rdf:li>'
[6.31] memberAttr ::= ' rdf:_n="' string '"' (where n is an integer)
[6.32] parseLiteral ::= ' parseType="Literal"'
[6.33] parseResource ::= ' parseType="Resource"'
[6.34] literal ::= (any well-formed XML)
El namespace formal para las propiedades y clases definidas en
esta especificación es
http://www.w3.org/1999/02/22-rdf-syntax-ns#.
Cuando un procesador RDF encuentra un elemento o nombre de atributo XML que está
declarado para constituir un namespace cuyo nombre comience por la
cadena "http://www.w3.org/TR/REC-rdf-syntax" y el
procesador no reconozca la semántica de dicho nombre, necesita saltar (es decir,
no generar tuplas para él) el elemento XML entero, incluyendo su contenido, cuyo
nombre no esté reconocido o que tenga un atributo cuyo nombre no se
reconozca.
Cada propertyElt E contenido por un elemento
Description tiene como resultado la creación de un triple
{p,r,v} donde:
-
p es la expansión del nombre de la etiqueta del
namespace apto (Identificador Genérico) de E. Esta expansión se genera
a través de la concatenación de nombres de namespace dados en una declaración
de namespace con el LocalPart del
nombre aceptado.
- r es
- el recurso cuyo identificador se da a través del valor del atributo
about de la descripción Description o
- un recurso nuevo cuyo identificador es el valor del atributo
ID de la descripción Description, en su
caso; de no ser así, el nuevo recurso no tiene identificador.
-
Si E es un elemento vacío (sin contenido), v
es el recurso cuyo identificador se da gracias al atributo
resource de E. Si el contenido de E no es
marcado XML o si parseType="Literal" se especifica en la
etiqueta inicial de E, entonces v es el contenido de E
(un literal). Por otra parte, el contenido de E debe ser otra
descripción [Description] o un contenedor y v es el
recurso nombrado por el (posiblemente implícito) ID o
about de dicho [elemento] Description o
contenedor.
El atributo parseType cambia la interpretación
del contenido del elemento. El atributo parseType debe tener uno
de los valores 'Literal' o 'Recurso'. El valor es diferente en mayúsculas o
minúsculas. El valor 'Literal' especifica que el contenido del elemento se
tratará como literal RDF/XML; esto es, el contenido no debe interpretarse por un
procesador RDF. El valor 'Recurso' especifica que dicho contenido del elemento
debe tratarse como si fuera el contenido de un elemento
Description. Otros valores de parseType se
reservan para especificación futura por RDF. Con RDF 1.0 otros valores deben
tratarse como un 'Literal' idéntico. En todos los casos, el contenido de un
elemento que tiene un atributo parseType debe ser XML bien
formado. El contenido de un elemento que tiene un atributo
parseType="Resource" debe además corresponder con la producción
para el contenido de un elemento Description.
El Grupo de trabajo dedicado al Modelo y la Sintaxis de RDF
agradece que el mecanismo parseType='Literal' sea una solución a nivel
mínimo para los requisitos necesarios para expresar una sentencia RDF con un
valor que tenga marcado XML. Complejidades adicionales de XML tales como
canonización de espacios en blanco no están bien definidas todavía. En el
trabajo futuro del W3C esperamos resolver dicho problema de una manera
uniforme para todas las aplicaciones basadas en XML. Las versiones futuras de
RDF heredarán este trabajo y pueden extenderlo al mismo tiempo que lleguemos a
un mayor entendimiento a través de la aplicación en experiencias
ulteriores.
Las referencias URI ser resuelven en un identificador de
recursos, primero resolviendo la referencia URI en forma absoluta como se
especifica en [URI]
utilizando el URI base del documento en el cual aparece la sentencia RDF. Si un
identificador de fragmento se incluye en la referencia URI, el identificador de
recursos se refiere sólo a un subcomponente del recurso contenedor; este
subcomponente se identifica a través del identificador de ancla interno hacia el
recurso que lo contiene y el alcance del subcomponente se define a través del
identificador de fragmento en conjunción con el tipo de contenido del recurso
que lo contiene, por otra parte el identificador del recurso se refiere al ítem
completo especificado por el URI.
Nota: A pesar de que los caracteres no-ASCII no están
permitidos en el [URI],
[XML] especifica una convención
para evitar incompatibilidades innecesarias en la sintaxis URI extendida. Los
implementadores de RDF están sensibilizados para evitar más incompatibilidades
y utilizan la convención XML para los identificadores del sistema.
Particularmente, aquellos caracteres no-ASCII en un URI están representados en
UTF-8 como uno o más bytes, de tal forma que estos bytes se solucionan con el
"mecanismo de escapatoria" [escaping mechanism] de URI (es decir,
convirtiendo cada byte en %HH, donde HH es la notación hexadecimal del valor
del byte).
El elemento Description en sí mismo es una
instancia [objeto específico de una categoría] de un recurso Bag. Los miembros
de este Bag son los recursos que corresponden con la reification
[transformación de algo abstracto en algo concreto] de cada una de las
sentencias en Description. Si el atributo bagID
se especifica, su valor es el identificador de ese Bag, incluso si el Bag es
anónimo.
Cuando se especifica about con
Description, la sentencia en el [elemento]
Description se refiere al recurso nombrado en el
about. Un elemento Description sin un atributo
about representa un recurso in-line. Este recurso in-line tiene
un identificador de recurso formado utilizando el valor de la base URI del
documento que contiene la sentencia RDF más un identificador de ancla igual al
valor del atributo ID del elemento Description,
en su caso. Cuando otro [elemento] Description o valor de
propiedad se refiere al recurso in-line utilizará el valor del
ID en un atributo about. Cuando el otro
Description se refiere al Bag del recurso que corresponde a la
sentencia que transforma algo abstracto en algo concreto [reified] se
utilizará el valor de bagID en un atributo
about. Tanto ID como about pueden
especificarse en el elemento Description pero no juntos en el
mismo elemento. Los valores para cada atributo ID y
bagID no deben aparecer en más de uno de tales atributos dentro
de un documento ni pueden [aparecer] el mismo valor usarse en un
ID y un bagID dentro de un documento
individual.
Cuando se especifica aboutEach con
Description, la sentencia en [el elemento]
Description se refiere a cada uno de los miembros del contenedor
denominado aboutEach. El triples {p,r,v} representado con
cada propertyElt E contenido, como se ha descrito anteriormente,
se duplican para cada r que es miembro del contenedor.
Cuando se especifica aboutEachPrefix con [el
elemento] Description, la sentencia en el
Description se refiere a cada uno de los miembros de un
contenedor Bag anónimo. Los miembros de ese contenedor Bag son todos los
recursos cuyo identificador de recursos en forma absoluta comienza con la cadena
de caracteres dada como valor del aboutEachPrefix.La forma
absoluta del identificador de recursos se produce a través de la resolución del
URI de acuerdo con el algoritmo en la Sección 5.2. Resolviendo Referencias
Relativas a Forma Absoluta, en [URI]. El triple {p,r,v} representado por
cada propertyElt E tal como se ha descrito anteriormente, se
duplican para cada uno de los miembros del contenedor.
Seq,
Bag, y Alt representan, cada uno, una instancia
[objeto específico de una categoría] de un tipo de recurso contenedor Sequence,
Bag, o Alternative, respectivamente. Se crea un triple {RDF:type,c,t}
donde c es el recurso que compendia y t es uno de RDF:Seq,
RDF:Bag, o RDF:Alt. Los miembro de la colección se denotan por
li. Cada elemento E li corresponde a un
miembro de la colección y resulta de la creación de un triple {p,c,v}
donde:
-
p se asigna paulatinamente de acuerdo con el orden
(XML) de apariencia léxica de cada miembro que empieza con "RDF:_1" para cada
contenedor.
-
c es el recurso que recopila. El atributo
ID, en el caso de que se especifique, proporciona el
identificador del fragmento URI para c.
-
(Misma regla 3 anterior) Si E es un elemento
vacío (sin contenido), v es el recurso cuyo identificador se da gracias
al atributo resource de E. Si el contenido de E
no es marcado XML o si parseType="Literal" se especifica
en la etiqueta inicial de E, entonces v es el contenido de
E (un literal). Por otra parte, el contenido de E debe ser otra
descripción [Description] o un contenedor y v es el
recurso nombrado por el (posiblemente implícito) ID o
about de dicho [elemento] Description o
contenedor.
El URI identifica (después de resuelto) el recurso objeto, es
decir, el recurso al cual se aplica Description o el recurso que
se incluye en el contenedor. El atributo bagID en un elemento
Description y el atributo ID en un
elemento contenedor permiten que [el elemento] Description o el
contenedor sean referenciados por otros Descriptions. El
ID en un elemento contenedor es el nombre que se usa en un
atributo resource en un elemento propiedad para hacer a la
colección el valor de dicha propiedad.
Dentro de propertyElt (producción [6.12]), el URI
utilizado en un atributo resource identifica (después de
resuelto) el recurso que es objeto de la sentencia (es decir, el valor de dicha
propiedad). El valor del atributo ID, si aparece especificado,
es el identificador para el recurso que representa la reification
[transformación de lo abstracto en concreto] de la sentencia. Si una expresión
RDF (esto es, contenido con marcado RDF/XML) se especifica como un valor de
propiedad el objeto es el recurso dado por el atributo about de
la Description contenida o el (posiblemente implicado)
ID de la Description contenida o el recurso
contenedor. Los Strings deben ser XML bien formado; el contenido
normal y los mecanismos de escape en XML pueden usarse si la cadena de
caracteres contiene secuencias de carácter (p. ej. "<" y "&") que violan
las reglas de la buena formación o que de lo contrario podrían parecer marcado.
El atributo parseType="Literal" especifica que el contenido del
elemento es un literal RDF. Cualquier marcado que sea parte de ese contenido se
incluye como parte del literal y no es interpretado por RDF.
Se recomienda que los nombres de las propiedades estén siempre
cualificados con un prefijo de namespace para conectar de forma inequívoca la
definición de la propiedad con el esquema correspondiente.
En tanto que está definido por XML, el repertorio de caracteres
de un string [o conjunto de caracteres] es ISO/IEC 10646 [ISO10646]. Un
string RDF actual, tanto en un documento XML o en otra representación del
modelo de datos RDF, puede almacenarse usando una codificación directa de
ISO/IEC 10646 o una codificación que pueda mapearse a ISO/IEC 10646. El lenguaje
de etiquetas [marcado] es parte del valor del string; se aplica a
secuencias de caracteres dentro de un string RDF y no tiene una
manifestación explícita en el modelo de datos.
Se estima que dos strings RDF son iguales si sus
representaciones ISO/IEC 10646 coinciden. Cada aplicación RDF debe
especificarse con una de las definiciones siguientes de "coincidencia" que
utilice:
- las dos representaciones son idénticas, o
- las dos representaciones son canónicamente equivalentes según se define en
el Unicode Standard [Unicode].
Nota: El W3C I18N
WG está trabajando en una definición para la coincidencia de identidad de
las secuencias de caracteres [string identity matching]. Esta
definición se basará, probablemente, en las equivalencias canónicas según el
estándar Unicode y en el principio de normalización uniforme antigua [early
uniform normalization]. Los usuarios de RDF no deben confiar en cualquier
aplicación que coincida utilizando los equivalentes canónicos, pero debe
intentar asegurarse de que sus datos están en la forma normalizada de acuerdo
con las próximas definiciones.
Esta especificación no establece un mecanismo para determinar
la equivalencia entre los literales que contiene el marcado, ni tampoco se
garantiza la existencia de un mecanismo tal.
El atributo xml:lang pude usarse
como se define en [XML] para asociar
un idioma con el valor de la propiedad. No hay una representación del modelo de
datos específica para xml:lang (es decir, no añade triples al
modelo de datos); el idioma de un literal se considera en RDF como una parte del
literal. Una aplicación puede ignorar el marcado de idioma de un string.
Todas las aplicaciones RDF deben especificar si el idioma de marcado en los
literales es significativo o no; esto es, si se considera o no el idioma cuando
se realiza la comprobación [matchig] de literales u otro
proceso.
Los atributos cuyos nombres empiezan con "xmlns" son
declaraciones de namespace y no representan triples en el modelo de datos. No
existe una representación de modelo de datos específico para cada declaración de
namespace.
Cada propiedad y valor expresados en forma de atributos XML por
procedimiento [6.3] y [6.10] es equivalente a la misma propiedad y valor
expresados como contenido XML del [elemento] Description
correspondiente de acuerdo al procedimiento [6.12]. Específicamente, cada
atributo A XML con una etiqueta de inicio Description en
vez de los atributos ID, about, aboutEach,
aboutEachPrefix, bagID, xml:lang, o cualquier
atributo que inicie con los caracteres xmlns da como resultado
la creación de un triple {p,r,v} donde:
-
p es la expansión del nombre del atributo del
namespace cualificado de A. Esta expansión se genera a través de la
concatenación del nombre del namespace dado en una declaración de namespace
con el LocalPart del
nombre cualificado y de esta forma resolviendo este URI de acuerdo con el
algoritmo de la Sección 5.2., Resolviendo Referencias Relativas a Forma
Absoluta, en [URI].
-
r es el recurso cuyo identificador de recurso se
expresa por el valor del atributo about, resuelto como se
especificó anteriormente, o cuyo id del ancla se expresa por el valor del
atributo ID de la descripción o es un miembro de la
colección especificada por un aboutEach o un atributo
aboutEachPrefix.
-
v es el valor del atributo de A (un
literal).
Gramaticalmente, la elaboración [6.11] es precisamente un caso
especial de la producción del propName [6.10]. El valor del atributo
type se interpreta como un URI de referencia y se expande de la
misma forma que el valor del atributo resource El uso de
[6.11] es equivalente a usar rdf:type como un
nombre de elemento (propiedad) junto con un atributo
resource.
La forma typedNode ([6.13]) puede usarse para
representar instancias [objetos específicos de una categoría] de un recurso de
tipos específicos y para describir además aquellos recursos. Un [elemento]
Description expresado por producción [6.3] con el mismo ID,
bagID, y atributo about más un tipo de propiedad
adicional en el Description donde el valor del tipo de propiedad
es el recurso cuyo identificador viene dado por el URI expandido y resuelto
completamente que corresponde con el typeName del typedNode.
Específicamente, un typedNode representa un triple {RDF:type,n,t} donde
n es el recurso cuyo identificador se expresa por el valor del atributo
about (después de resuelto) o cuyo id del ancha se expresa por
el valor del atributo ID del elemento typedNode, y t es
el nombre de la etiqueta del namespace cualificado. El resto de los atributos y
contenido typedNode se maneja igual que para el elemento
Description citado anteriormente.
Las propiedades y valores expresados en forma de atributo XML
dentro de un elemento XML vacío E por producciones [6.10] y [6.12] son
equivalentes a las mismas propiedades y valores expresados como contenido XML en
un elemento individual D Description que puede se
convertiría en el contenido de E. El referente de D es el valor de
la propiedad identificada pro el nombre del elemento XML de E según
[6.17], [6.2], y [6.3]. Específicamente, cada etiqueta inicial propertyElt
que contenga especificaciones de atributos distintas a ID,
resource, bagID, xml:lang, u otro atributo que
comience con los caracteres xmlns da como resultado la creación de
triples {p,r1,r2},
{pa1,r2,va1}, ...,
{pan,r2,van} donde:
- p es la expansión de la etiqueta del namespace cualificado.
- r1 es el recurso que está siendo referenciado por el
elemento que contiene esta expresión propertyElt.
- r2 es el recurso denominado por el atributo
resource en su caso, o a un nuevo recurso. Si se da el
atributo ID es el identificador de ese nuevo recurso.
- pa1 ... pan son las expansiones de los
nombres de atributo del namespace cualificado.
- va1 ... van son los valores de atributo
correspondientes.
El valor del atributo bagID, en su caso, es el
identificador para el Bag que corresponde con el Description
D; si no el Bag es anónimo.
7. Ejemplos
Los ejemplos siguientes ilustrarán más
ampliamente las características de RDF explicadas anteriormente.
7.1. Valores compartidos
Un recurso individual puede ser el valor de más de una
propiedad, esto es, puede ser objeto de más de una sentencia y por consiguiente
apuntar a más de un arco. Por ejemplo, una página web individual puede
compartirse entre varios documentos y puede así referenciarse más de una vez en
el mapa te un sitio ["sitemap"]. O se pueden dar dos secuencias
diferentes (ordenadas) del mismo recurso.
Considere el caso de la especificación de los trabajos
recopilados de un autor, ordenados una vez por fecha de publicación y otra vez
alfabéticamente por materias:
<RDF xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<Seq ID="JSPapersByDate">
<li resource="http://www.dogworld.com/Aug96.doc"/>
<li resource="http://www.webnuts.net/Jan97.html"/>
<li resource="http://www.carchat.com/Sept97.html"/>
</Seq>
<Seq ID="JSPapersBySubj">
<li resource="http://www.carchat.com/Sept97.html"/>
<li resource="http://www.dogworld.com/Aug96.doc"/>
<li resource="http://www.webnuts.net/Jan97.html"/>
</Seq>
</RDF>
Este ejemplo XML utiliza también la sintaxis de
declaración del namespace por defecto para elidir el prefijo namespace.
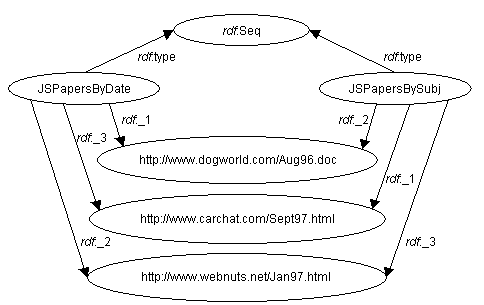 D
Figura 13: Valores compartidos entre dos secuencias.
D
Figura 13: Valores compartidos entre dos secuencias.
7.2. Conjuntos [Aggregates]
Para ilustrar más ampliamente los conjuntos, considere un
ejemplo de un documento con dos autores especificados alfabéticamene, un título
especificado en dos idiomas diferentes, y que tiene dos ubicaciones distintas en
la Web:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/metadata/dublin_core#">
<rdf:Description about="http://www.foo.com/cool.html">
<dc:Creator>
<rdf:Seq ID="CreatorsAlphabeticalBySurname">
<rdf:li>Mary Andrew</rdf:li>
<rdf:li>Jacky Crystal</rdf:li>
</rdf:Seq>
</dc:Creator>
<dc:Identifier>
<rdf:Bag ID="MirroredSites">
<rdf:li rdf:resource="http://www.foo.com.au/cool.html"/>
<rdf:li rdf:resource="http://www.foo.com.it/cool.html"/>
</rdf:Bag>
</dc:Identifier>
<dc:Title>
<rdf:Alt>
<rdf:li xml:lang="en">The Coolest Web Page</rdf:li>
<rdf:li xml:lang="it">Il Pagio di Web Fuba</rdf:li>
</rdf:Alt>
</dc:Title>
</rdf:Description>
</rdf:RDF>
Este ejemplo ilustra el uso de los tres tipos de colecciones.
El orden de los creadores se ha estimado significativo, por ello se usa el
contenedor Sequence para expresarlo. Las ubicaciones en la Web son
equivalentes; el orden [en este caso] no es significativo, por ello se utiliza
Bag. El documento tiene sólo un título y ese título dos variantes, por
ello se utiliza el contenedor Alternatives.
Nota: En muchos casos es imposible tener un idioma preferente
entre varios alternativos, todos los idiomas se considaran estrictamente
equivalentes. En estos casos, el autor de la descripción debe utilizar
Bag en lugar del contenedor Alt.
7.3. Relaciones no binarias
El modelo de datos RDF intrínsecamente sólo soporta relaciones
binarias, esto es, una sentencia especifica un relación entre dos recursos. En
los ejemplos siguientes mostramos la forma recomendada para representar
relaciones de mayor complejidad [higher arity] en RDF utilizando sólo
relaciones binarias. La técnica recomendada es utilizar un recurso intermedio
con propiedades adicionales de este recurso expresando las relaciones restantes.
Como ejemplo, considere la materia de uno de los artículos recientes de John
Smith's--biblioteconomía--. Podemos utilizar el Código Decimal de Dewey para
biblioteconomía para categorizar o clasificar dicho artículo. Los códigos de la
clasificación Decimal de Dewey distan mucho de ser un sólo esquema de
categorización, por ello para mantener la relación del sistema de clasificación
identificamos un recurso adicional que es usa como el valor de la propiedad
materia y anota este recurso con una propiedad adicional que identifica el
esquema de categorización utilizado. Como se especifica en la Sección 2.3. el
núcleo de RDF incluye un valor 'propiedad' para denotar el valor principal de la
relación principal. El gráfico resultante podría parecer así:
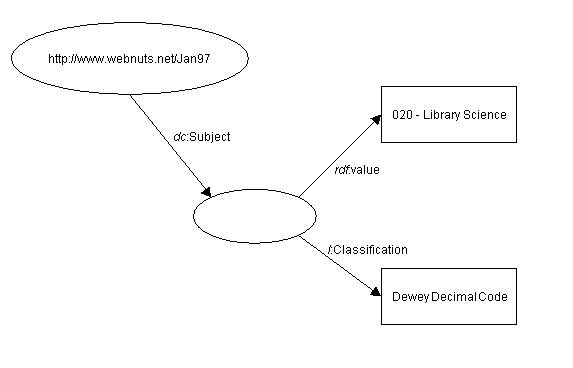 D
Figure 14: Una relación ternaria
D
Figure 14: Una relación ternaria
que podría cambiarse así:
<RDF
xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/metadata/dublin_core#"
xmlns:l="http://mycorp.com/schemas/my-schema#">
<Description about="http://www.webnuts.net/Jan97.html">
<dc:Subject
rdf:value="020 - Library Science"
l:Classification="Dewey Decimal Code"/>
</Description>
</RDF>
Nota: En el ejemplo anterior existen dos declaraciones de
namespace para el mismo namespace. Esto es necesario con frecuencia cuando el
namespace por defecto se declara de tal forma que los atributos que no
provienen del namespace del elemento pueden especificarse, si se da el caso
con el atributo rdf:value en el elemento citado anteriormente
dc:Subject.
Un uso común de esta capacidad mayor [higher-arity] se
relaciona con unidades de medida. El peso de una persona no es exactamente algo
como "200", también incluye la unidad de medida utilizada. En este caso
podríamos utilizar tanto libras como kg. Podríamos usar una relación con un arco
adicional para registrar el hecho de que John Smith es un cabellero bastante
robusto:
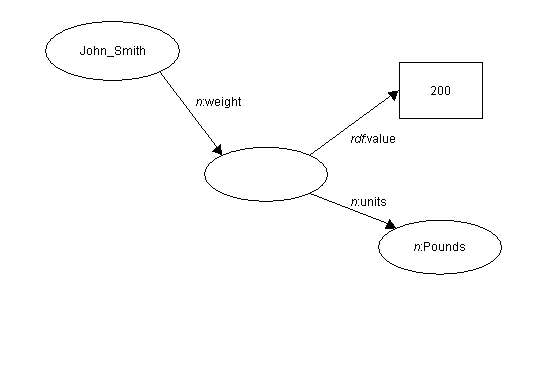 D
Figura 15: Unidad de medida como relación terneria
D
Figura 15: Unidad de medida como relación terneria
que puede sustituirse por:
<RDF
xmlns="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:n="http://www.nist.gov/units/">
<Description about="John_Smith">
<n:weight rdf:parseType="Resource">
<rdf:value>200</rdf:value>
<n:units rdf:resource="http://www.nist.gov/units/Pounds"/>
</n:weight>
</Description>
</RDF>
siempre que el recurso "Pounds" se defina en un esquema
NIST con el URI http://www.nist.gov/units/Pounds.
7.4. Metadatos Dublin Core
Los metadatos Dublin Core se
diseñaron para facilitar la recuperación de recursos electrónicos de forma
similar a una ficha de catálogo en las bibliotecas. Estos ejemplos representan
la descripción simple de un conjunto de recursos en RDF que utilizan los
vocabularios definidos por la Iniciativa Dublin Core. Nota:
el vocabulario RDF específico para el Dublin Core mostrado aquí no tiene la
intención de tomarse como autoridad. La Iniciativa del Dublin Core es la
referencia de autoridad.
Aquí se presenta una descripción de un sitio Web utilizando las propiedades
del Dublin Core:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/metadata/dublin_core#">
<rdf:Description about="http://www.dlib.org">
<dc:Title>D-Lib Program - Research in Digital Libraries</dc:Title>
<dc:Description>The D-Lib program supports the community of people
with research interests in digital libraries and electronic
publishing.</dc:Description>
<dc:Publisher>Corporation For National Research Initiatives</dc:Publisher>
<dc:Date>1995-01-07</dc:Date>
<dc:Subject>
<rdf:Bag>
<rdf:li>Research; statistical methods</rdf:li>
<rdf:li>Education, research, related topics</rdf:li>
<rdf:li>Library use Studies</rdf:li>
</rdf:Bag>
</dc:Subject>
<dc:Type>World Wide Web Home Page</dc:Type>
<dc:Format>text/html</dc:Format>
<dc:Language>en</dc:Language>
</rdf:Description>
</rdf:RDF>
El segundo ejemplo es de una revista publicada. <rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/metadata/dublin_core#"
xmlns:dcq="http://purl.org/metadata/dublin_core_qualifiers#">
<rdf:Description about="http://www.dlib.org/dlib/may98/05contents.html">
<dc:Title>DLIB Magazine - The Magazine for Digital Library Research
- May 1998</dc:Title>
<dc:Description>D-LIB magazine is a monthly compilation of
contributed stories, commentary, and briefings.</dc:Description>
<dc:Contributor rdf:parseType="Resource">
<dcq:AgentType
rdf:resource="http://purl.org/metadata/dublin_core_qualifiers#Editor"/>
<rdf:value>Amy Friedlander</rdf:value>
</dc:Contributor>
<dc:Publisher>Corporation for National Research Initiatives</dc:Publisher>
<dc:Date>1998-01-05</dc:Date>
<dc:Type>electronic journal</dc:Type>
<dc:Subject>
<rdf:Bag>
<rdf:li>library use studies</rdf:li>
<rdf:li>magazines and newspapers</rdf:li>
</rdf:Bag>
</dc:Subject>
<dc:Format>text/html</dc:Format>
<dc:Identifier>urn:issn:1082-9873</dc:Identifier>
<dc:Relation rdf:parseType="Resource">
<dcq:RelationType
rdf:resource="http://purl.org/metadata/dublin_core_qualifiers#IsPartOf"/>
<rdf:value resource="http://www.dlib.org"/>
</dc:Relation>
</rdf:Description>
</rdf:RDF>
El tercer ejemplo es de un artículo específico en
la revista aludida en el ejemplo anterior. <rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/metadata/dublin_core#"
xmlns:dcq="http://purl.org/metadata/dublin_core_qualifiers#">
<rdf:Description about=
"http://www.dlib.org/dlib/may98/miller/05miller.html">
<dc:Title>An Introduction to the Resource Description Framework</dc:Title>
<dc:Creator>Eric J. Miller</dc:Creator>
<dc:Description>The Resource Description Framework (RDF) is an
infrastructure that enables the encoding, exchange and reuse of
structured metadata. rdf is an application of xml that imposes needed
structural constraints to provide unambiguous methods of expressing
semantics. rdf additionally provides a means for publishing both
human-readable and machine-processable vocabularies designed to
encourage the reuse and extension of metadata semantics among
disparate information communities. the structural constraints rdf
imposes to support the consistent encoding and exchange of
standardized metadata provides for the interchangeability of separate
packages of metadata defined by different resource description
communities. </dc:Description>
<dc:Publisher>Corporation for National Research Initiatives</dc:Publisher>
<dc:Subject>
<rdf:Bag>
<rdf:li>machine-readable catalog record formats</rdf:li>
<rdf:li>applications of computer file organization and
access methods</rdf:li>
</rdf:Bag>
</dc:Subject>
<dc:Rights>Copyright @ 1998 Eric Miller</dc:Rights>
<dc:Type>Electronic Document</dc:Type>
<dc:Format>text/html</dc:Format>
<dc:Language>en</dc:Language>
<dc:Relation rdf:parseType="Resource">
<dcq:RelationType
rdf:resource="http://purl.org/metadata/dublin_core_qualifiers#IsPartOf"/>
<rdf:value resource="http://www.dlib.org/dlib/may98/05contents.html"/>
</dc:Relation>
</rdf:Description>
</rdf:RDF>
Nota: Los desarrolladores del esquema pueden estar tentados
en declarar los valores de ciertas propiedades para usar una sintaxis que
corresponda al XML. La abreviatura del nombre cualificado del namespace [qualified name].
Aconsejamos no utilizar estos nombres cualificados dentro de los valores de
propiedad en tanto que pueden causar incompatibilidades con los mecanismos de
tipificación de datos futuros en XML. Además, aquellos versados en las
características de XML 1.0 pueden reconocer que un mecanismo de abreviatura
similar existe en las entidades definidas por el usuario. También aconsejamos
no fiarse del uso de entidades en tanto que existe una propuesta para definir
un futuro subconjunto de XML, que no incluya entidades definidas por el
usuario.
7.5. Valores que contienen marcado
Cuando un valor de propiedad es un literal que contiene marcado
XML, la sintaxis siguiente se utiliza para señalar al intérprete RDF que no
interprete el marcado más bien para conservarlo como parte del valor. La
representación precisa del valor resultante no se especifica aquí.
En el ejemplo siguiente, el valor de la propiedad título [title] es un
literal que contiene algún macado MATHML.
<rdf:Description
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/metadata/dublin_core#"
xmlns="http://www.w3.org/TR/REC-mathml"
rdf:about="http://mycorp.com/papers/NobelPaper1">
<dc:Title rdf:parseType="Literal">
Ramifications of
<apply>
<power/>
<apply>
<plus/>
<ci>a</ci>
<ci>b</ci>
</apply>
<cn>2</cn>
</apply>
to World Peace
</dc:Title>
<dc:Creator>David Hume</dc:Creator>
</rdf:Description>
7.6. Etiquetas PICS
La Plataforma para la Selección del Contenido de Internet [ Platform for Internet Content
Selection (PICS)] es una Recomendación del W3C para intercambiar
descripciones de contenido de las páginas Web y otros materiales. PICS es un
predecesor de RDF y es un requisito explícito de RDF que sea capaz de expresar
cualquier cosa que se pueda expresar a través de una etiqueta PICS.
Esta es un ejemplo de cómo una etiqueta PICS podría expresarse
en forma RDF. Nótese que el trabajo para re-especificar los PICS como una
aplicación de RDF puede conllevar la terminación de la especificación RDF, por
ello el ejemplo siguiente no debe considerarse un ejemplo autorizado de un
esquema futuro de PICS. Este ejemplo proviene directamente de los [PICS]. Nótese que una Rating Service Description de
los PICS es exactamente análoga a un Esquema RDF; las categorías descritas en
este fichero de descripción del Servicio de Evaluación son equivalentes a las
propiedades en el modelo RDF.
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pics="http://www.w3.org/TR/xxxx/WD-PICS-labels#"
xmlns:gcf="http://www.gcf.org/v2.5">
<rdf:Description about="http://www.w3.org/PICS/Overview.html" bagID="L01"
gcf:suds="0.5"
gcf:density="0"
gcf:color.hue="1"/>
<rdf:Description about="http://www.w3.org/PICS/Underview.html" bagID="L02"
gcf:subject="2"
gcf:density="1"
gcf:color.hue="1"/>
<rdf:Description aboutEach="#L01"
pics:by="John Doe"
pics:on="1994.11.05T08:15-0500"
pics:until="1995.12.31T23:59-0000"/>
<rdf:Description aboutEach="#L02"
pics:by="Jane Doe"
pics:on="1994.11.05T08:15-0500"
pics:until="1995.12.31T23:59-0000"/>
</rdf:RDF>
Nótese que aboutEach se usa para idndicar que
las pociones de la etiqueta PICS se refieren a la sentencia (evaluada)
individualmente y no al contenedor en el que dichas sentencias llegarán a
sustituirse.
[PICS]
también define un tipo denominado generic label [etiqueta genérica]. Una
etiqueta genérica PICS es aquella que se aplica a cada página dentro de una
parte específica de un sitio Web.
A continuación se presenta un ejemplo de cómo una etiqueta
genérica PICS se escribiría en RDF, utilizando el constructor de colecciones
aboutEachPrefix. Este ejemplo se ha estraído del ejemplo de
"Generic request" en el apéndice B de los [PICS]:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pics="http://www.w3.org/TR/xxxx/WD-PICS-labels#"
xmlns:ages="http://www.ages.org/our-service/v1.0/">
<rdf:Description aboutEachPrefix="http://www.w3.org/WWW/" bagID="L03"
ages:age="11"/>
<rdf:Description aboutEach="#L03"
pics:by="abaird@w3.org"/>
</rdf:RDF>
La propiedad edad age con el valor "11" aparece
en cada recurso cuyo URI empieza con la secuencia [string]
"http://www.w3.org/WWW/". La sentencia "reificada" [concretada,
reified] que corresponde a cada una de tales sentencias
"La edad de
[I] es 11" ("The age of [I] is 11") tiene una propiedad que afirma
que "abaird@w3.org" fue el responsable de la creación de dicha
sentencia.
7.7. Contenido que se oculta para RDF dentro de
HTML
RDF, si es XML bien formado, es adecuado para la inclusión
directa en un documento HTML cuando el agente de usuario sigue las
recomendaciones para el manejo de errores en documentos no válidas [recommendations
for error handling in invalid documents] del HTML. Cuando un fragmento de
RDF se incorpora en un documento, algunos navegadores crean automáticamente
algunos strings de contenido expuestos. Los contenidos del string
expuesto es todo lo que aparece entre el ">" que finaliza una etiqueta y el
"<" que inicia la siguiente etiqueta. Generalmente, múltiples espacios en
blanco consecutivos, incluyendo caracteres de final de línea, se toman como
espacios simples.
Normalmente puede utilizarse la sintaxis abrevidada de RDF para
escribir los valores de propiedad que son strings en forma de un atributo
XML y deja sólo un espacio en blanco como contenido expuesto. Por ejemplo, la
primera parte del ejemplo del Dublin Core de la Sección 7.4 podría escribirse
así:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/metadata/dublin_core#">
<rdf:Description about="http://www.dlib.org"
dc:Title="D-Lib Program - Research in Digital Libraries"
dc:Description="The D-Lib program supports the community of people
with research interests in digital libraries and electronic
publishing."
dc:Publisher="Corporation For National Research Initiatives"
dc:Date="1995-01-07"/>
</rdf:RDF>
Rescrito para evitar el contenido expuesto, trabajará para más
casos comunes. Un caso común pero menos obvio son las descripciones de
contenedores. Considerar la primera parte del ejemplo en la Sección
7.2.:
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/metadata/dublin_core#">
<rdf:Description about="http://www.foo.com/cool.html">
<dc:Creator>
<rdf:Seq ID="CreatorsAlphabeticalBySurname">
<rdf:li>Mary Andrew</rdf:li>
<rdf:li>Jacky Crystal</rdf:li>
</rdf:Seq>
</dc:Creator>
</rdf:Description>
</rdf:RDF>
Para rescribir esto con contenido no expuesto,
utilizamos la forma siguiente: <rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/metadata/dublin_core#">
<rdf:Description about="http://www.foo.com/cool.html">
<dc:Creator>
<rdf:Seq ID="CreatorsAlphabeticalBySurname"
rdf:_1="Mary Andrew"
rdf:_2="Jacky Crystal"/>
</dc:Creator>
</rdf:Description>
</rdf:RDF>
Nótese que aquí el elemento li no puede usarse
como un atributo debido a que la regla de XML prohibe múltiples ocurrencias del
mismo nombre de atributo dentro de una etiqueta. Por consiguiente utilizamos las
propiedades explícitas de RDF Ord; en efecto de que se expanda
manualmente el elemento li.
Un documento HTML completo que contenga los metadatos RDF que lo describan
es:
<html>
<head>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:dc="http://purl.org/metadata/dublin_core#">
<rdf:Description about="">
<dc:Creator>
<rdf:Seq ID="CreatorsAlphabeticalBySurname"
rdf:_1="Mary Andrew"
rdf:_2="Jacky Crystal"/>
</dc:Creator>
</rdf:Description>
</rdf:RDF>
</head>
<body>
<P>This is a fine document.</P>
</body>
</html>
El documento HTML anterior debe aceptarse en todos los
navegadores compatibles con HTML 3.2 y versiones posteriores y debe mostrar sólo
los caracteres: "This is a fine document."
8. Agradecimientos
Esta especificación el el trabajo del Grupo de Trabajo sobre el
Modelo y la Sintaxis RDF del W3C. Este grupo de trabajo ha sido dirigido
ábilmente por Eric Miller de Online Computer Library Center [OCLC] y Bob Schloss
de IBM. Agradecemos a Eric y a Bob por su esfuerzo infatigable por mantener al
grupo sobre la pista y agracedemos especialmente a OCLC, IBM, y Nokia por
soportarlos a ellos y a nosotroes en este empeño.
Los miembros del Grupo de Trabajo que ayudaron a diseñar esta
especificación, debatir propuestas, proporcionar palabras, corregir numerosos
borradores y finalmente, conseguir consenso, son: Ron Daniel (DATAFUSION),
Renato Iannella (DSTC), Tsuyoshi SAKATA (DVL), Murray Maloney (Grif), Bob
Schloss (IBM), Naohiko URAMOTO (IBM), Bill Roberts (KnowledgeCite), Arthur van
Hoff (Marimba), Charles Frankston (Microsoft), Andrew Layman (Microsoft), Chris
McConnell (Microsoft), Jean Paoli (Microsoft), R.V. Guha (Netscape), Ora Lassila
(Nokia), Ralph LeVan (OCLC), Eric Miller (OCLC), Charles Wicksteed (Reuters),
Misha Wolf (Reuters), Wei Song (SISU), Lauren Wood (SoftQuad), Tim Bray
(Textuality), Paul Resnick (University of Michigan), Tim Berners-Lee (W3C), Dan
Connolly (W3C), Jim Miller (W3C, emérito), Ralph Swick (W3C). Dan Brickley (UK
Bristol) se han unido a la actividad del Esquema RDF y nos traen muchos sabios
consejos en los estadios finales de este trabajo. Martin Dürst (W3C) revisó
varios borradores de trabajo e hizo numerosa propuestas para mejorar, en nombre
del W3C el grupo de Internacionalización [Internationalization Working Group].
Janne Saarela (W3C) desempeñó un serviciode gran valor creando una versión más
clara ['clean room' implementation] de
nuestros borradores de trabajo.
Este documento es el trabajo colectivo del Grupo de Trabajo.
Los editores agradecen al Grupo de trabajo la ayuda prestada para crear y pulir
esta especificación.
Apéndice A. Glosario
Los términos siguientes se utilizan en esta especificación con
distintos grados de significado intuitivo y significado preciso. El compendio de
definiciones aquí son sólo como guía; no son normativas. En el lugar apropiado,
se da la localización en el documento de definiciones precisas.
- Arco [Arc]
-
Una representación de una propiedad en forma gráfica;
específicamente los bordes en un gráfico etiquetado directamente.
- Atributo [Attribute]
-
Una característica de un objeto. En el Capítulo 6 este
término se refiere a una construcción sintáctica específica de XML; las
porciones name="value" [nombre="valor"] de una etiqueta
XML.
- Elemento [Element]
-
Como se utiliza aquí, este término se refiere a una
construcción específica de XML, es decir el material entre las etiquetas XML
de inicio y de fin.
- Literal [Literal]
-
El tipo de valor más primitivo representado en RDF,
típicamente una cadena [string] de caracteres. El contenido de un
literal no es interpretado por RDF en sí mismo y puede contener marcado XML
adicional. Los literales se distinguen de los recursos en que el modelo RDF no
permite que los literales sean sujeto de una sentencia.
- Nodo [Node]
-
Una representación de un recurso o un literal en forma
gráfica; específicamente, un vértice en un gráfico etiquetado
directamente.
- Propiedad
[Property]
-
Un atributo específico con significado definido que puede
utilizarse para describir otros recursos. Una propiedad más el valor de dicha
propiedad para un recurso específico es un sentencia [statement] sobre
ese recurso. Una propiedad puede definir sus valores permitidos así como los
tipos de recursos que pueden describirse con esa propiedad.
- Recurso
[Resource]
-
Un objeto abstracto que representa tanto un objeto físico
como una persona o un libro como un objeto conceptual como un color o la clase
de cosas que tienen colores. Las páginas Web se consideran normalmente objetos
físicos, pero la distinción entre un objeto conceptual o abstracto no es
importante en RDF. Un recurso puede también ser un componente de un objeto
mayor; por ejemplo, un recurso puede representar la mano izquierda de
una persona específica o un párrafo específico de un documento. Como se usa en
esta especificación, el término recurso se refiere a la totalidad de un objeto
si el URI no contiene un fragmento id [identificador] (ancla) o para la
subunidad específica denominada por el fragmento o el id del ancla.
- Sentencia
[Statement]
-
Una expresión que sigue una gramática específica que
denomina un recurso específico, una propiedad (atributo) específico, y
proporciona el valor de dicha propiedad para tal recurso. Más
específicamente aquí, una sentencia RDF es una sentencia que utiliza la
gramática RDF/XML especificada en este documento.
- Triple
[Triple]
-
Una representación de una sentencia usada por RDF, que
consiste exactamente en la propiedad, el identificador del recurso, y el valor
de la propiedad, en ese orden.
Apéndice B. Trasladando RDF
Las descripciones
pueden asociarse con el recurso que describen en una de estas cuatro formas:
- La Descripción puede contenerse dentro del recurso( [embebido] "embedded";
ej.
en HTML).
- La Descripción puede ser externa al recurso pero proporcionada por el
mecanismo de transferencia en la misma transacción de recuperación que
devuelve el recurso ([junto a] "along-with"; ej. con HTTP GET o HEAD).
- La Descripción puede recuperarse independientemente del recurso,
incluso desde un recurso diferente ([servicio oficina] "service bureau"; ej.
utilizando HTTP GET).
- La Descripción puede contener el recurso ([envuelto] "wrapped"; ej.RDF a
sí mismo).
Todos los recursos no soportarán todos los métodos de
asociación; en particular, muchas clases de recursos no soportarán embeberse y
sólo algunas clases de recursos permitirán envolverse.
Una descripción entendible por el hombre --o la máquina-- de un
esquema RDF puede accederse a través de la gestión de contenido referenciando el
esquema URI. Si el esquema es legible por máquina puede que una aplicación pueda
aprender algo de la semántica de las propiedades denominadas en el esquema a
petición. La lógica y la sintaxis de los esquemas RDF se describen en un
documento a parte, [RDFSchema].
La técnica recomendada para embeber expresiones RDF en un
documento HTML es simplemente insertar el RDF in-line como muestra el ejemplo
7.7. Esto hará al documento resultante no conforme con las especificaciones HTML
hasta e incluyendo HTML 4.0 pero el W3C prevé que la especificación de HTML
evolucionará [the HTML specification
will evolve] para soportarlo. Dos problemas prácticos surgirán cuando esta
técnica se emplee con respecto a la conformidad de los navegadores con la
especificación del HTML hasta e incluyendo HTML 4.0. Los autores disponen de
alternativas accesibles en estos casos, ver [XMLinHTML]. El autor está dispuesto a
elegir la alternativa apropiada en cada circunstancia.
-
Algunos navegadores HTML 2.0 asumirán una etiqueta
</HEAD> inmediatamente antes del primer elemento RDF que aparece en el
<HEAD>.
Los autores preocupados por los navegadores muy antiguos
deben reemplazar todas las expresiones RDF al final de la cabecera del
documento.
-
Todos los navegadores HTML conformes con las especificaciones
hasta e incluida la HTML 4.0 crearán automáticamente cualquier contenido
que aparezca en los valores de propiedad RDF expresados como elementos XML (es
decir, producción [6.12]).
Los autores preocupados por la prevención del contendido RDF
de la visualización en navegadores antiguos deben usar la sintaxis abreviada
(forma propAttr) para cambiar el valor de una propiedad por un atributo. No
todas las propiedades pueden expresarse de esta forma.
En el caso de que ninguna de las alternativas anteriores
proporcione las capacidades deseadas por el autor, las expresiones RDF pueden
dejarse como externas al documento HTML y unidas con un elemento
<LINK> de HTML. El tipo de relación recomendada para esta propuesta
es REL="meta"; ej.
<LINK rel="meta" href="mydocMetadata.DC.RDF">
Apéndice C: Notas sobre el Uso
C.1. Nombres de las Propiedades [Property Names]
Las sintaxis serializada y abreviada de RDF utilizan XML como
codificación. Los elementos y atributos XML son sensibles a las mayúsculas y
minúsculas, por ello los nombres de las propiedades RDF son también sensibles a
las mayúsculas y minúsculas. Esta especificación no requiere ningún formato
específico para los nombres de propiedad a parte de que sean nombres XML legales
[names]. Para sus
propios identificadores, RDF ha adoptado la convención de que todos los nombres
de propiedad usan "InterCap style"; esto es, la primera letra del nombre de la
propiedad y el resto de la palabra en minúsculas; ej. subject. Cuando el
nombre de la propiedad es un compuesto de palabras o fragmentos de palabras, las
palabras se concatenan con la primera letra de cada palabra (excepto la primera
palabra) en mayúscula y sin puntuación adicional, ej.
subClassOf.
C.2. Namespace URIs
RDF utiliza al mecanismo de namespaces propuesto en XML para
implementar globalmente identificadores únicos para todas las propiedades. En
resumen, el nombre del namespace sirve como el identificador del correspondiente
esquema RDF. El nombre del namespace se resuelve en forma absoluta como se
especifica por el algoritmo en la Sección 5.2., Resolviendo Referencias
Relativas a Forma Absoluta, en [URI]. Un procesador RDF puede prever el uso del
URI del esquema para acceder al contenido del esquema. Esta especificación no
precisa más requerimientos en el contenido, que podrían ser proporcionados en
dicho URI, tampoco precisa cómo (si en absoluto) el URI podría modificarse para
obtener formas alternativas o un fragmento del esquema.
Apéndice D: Referencias
- [Dexter94]
- F. Halasz and M. Schwarz. The Dexter Hypertext Reference Model.
Communications of the ACM, 37(2):30--39, February 1994. Edited by K. Grønbæck
and R. Trigg. http://www.acm.org/pubs/citations/journals/cacm/1994-37-2/p30-halasz/
- [HTML]
- HTML 4.0 Specification, Raggett, Le Hors, Jacobs eds, World Wide Web
Consortium Recommendation; http://www.w3.org/TR/REC-html40/
- [ISO10646]
- ISO/IEC 10646. The applicable version of this standard is defined in the
XML specification [XML].
- [NAMESPACES]
- Namespaces in XML; Bray, Hollander, Layman eds, World Wide Web Consortium
Recommendation; http://www.w3.org/TR/1999/REC-xml-names-19990114.
- [PICS]
- PICS Label Distribution Label Syntax and Communication Protocols, Version
1.1, W3C Recommendation 31-October-96; http://www.w3.org/TR/REC-PICS-labels.
- [RDFSchema]
- Resource Description Framework (RDF) Schemas; Brickley, Guha, Layman eds.,
World Wide Web Consortium Working Draft; rdfsch.htm
- [RFC2119]
- Key words for use in RFCs to Indicate Requirement Levels; S. Bradner,
March 1997; RFC2119.
- [Unicode]
- The Unicode Standard. The applicable version of this standard is the
version defined by the XML specification [XML].
- [URI]
- Uniform Resource Identifiers (URI): Generic Syntax; Berners-Lee, Fielding,
Masinter, Internet Draft Standard August, 1998; RFC2396.
- [XML]
- Extensible Markup Language (XML) 1.0; World Wide Web Consortium
Recommendation; http://www.w3.org/TR/REC-xml.
- [XMLinHTML]
- XML in HTML Meeting Report; Connolly, Wood eds.; World Wide Web Consortium
Note; http://www.w3.org/TR/NOTE-xh.
Apéndice E: Cambios
Se han realizado algunos cambios tipográficos después de que se
publicara la Propuesta de Recomendación [Proposed Recommendation]. Las
erratas detectadas en la versión previa como en el tiempo de publicación, se han
corregido. Se hizo un pequeño cambio clarificador al párrafo final de las
Sección 6.
Ora Lassila <ora.lassila@research.nokia.com>
Ralph R. Swick <swick@w3.org>
Historial de Revisiones:
17-febrero-1999: preparado para la publicación como Recomendación del
W3C.
5-enero-1999: publicado como Propuesta de
Recomendación del W3C.
16-diciembre-1998: intento de
borrador final como Recomendación Propuesta.
30-octubre-1998: incorporación de la última llamada para comentarios de
revisión, añadir parseType, mejora del " I18N wordings".
8-octubre-1998: corrección final, se mueven cambios al apéndice E, se
publica como "Last Call" (última llamada).
7-octubre-1998: se reserva un poco del esquema del espacio URI para
pruebas futuras, se añade rdf:value.
2-octubre-1998:
denominaciones principales: sentencias, predicados, sujetos, objetos.
4-septiembre-1998: instanceOf -> type, se revisa el modelo
de relaciones higher-arity, se añade el identificador de nodos.
19-agosto-1998: se añade '_' para ordenar los
nombres de las propiedades.
12-agosto-1998:
actualización relacionada con la sintaxis de declaración de namespace en XML. Se
añade contenido a la Sección 7.
20-julio-1998: Se fijan
más tipos. Tercer borrador público.
15-julio-1998: Se
incorporan comentarios y se fijan tipos. La letra inicial de los nombres
de propiedades se cambia a minúscula.
15-junio-1998: Principal material escrito y reorganización.
16-febrero-1998: Corrección editorial, preparada para la
segunda distribución pública.
6-febrero-1998:
Corrección editorial, se añaden y se revisan algunos ejemplos.
11-enero-1998: Se renombran y se desestiman algunos elementos.
14-noviembre-1997: Mayor refinamiento, especialmente en
relación con las afirmaciones
3-noviembre-1997:
Revisión de la edición en preparación para la segunda distribución
pública
2-octubre-1997: Primer borrador público
1-octubre-1997: Revisión de la edición en preparación para la
primera distribución pública.
1-agosto-1997: Primer
borrador del Grupo de Trabajo.
Última actualización: $Date: 1999/02/24 14:45:07 $
Última actualización de la
traducción: $Date: 2001/01/03 02:43:10 $
Otras traducciones de este documento: